A glimpse at Spark
LPSM Université Paris-Cité
Spark in perspective
From the archive
- Spark project
-
launched in 2010 by M. Zaharia (UC Berkeley) et al.
- Spark 1.0.0 released (May 30, 2014):
-
… This release expands Spark’s standard libraries, introducing a new SQL package (Spark SQL) that lets users integrate SQL queries into existing Spark workflows. MLlib, Spark’s machine learning library, is expanded with sparse vector support and several new algorithms. The GraphX and Streaming libraries also introduce new features and optimizations. Spark’s core engine adds support for secured YARN clusters, a unified tool for submitting Spark applications, and several performance and stability improvements.
- Spark 2.0.0 released (July 26, 2016)
-
The major updates are API usability, SQL 2003 support, performance improvements, structured streaming, R UDF support, as well as operational improvements.
From the archive (continued)
- Spark 3.0.0 released (June 18, 2020)
-
… This year is Spark’s 10-year anniversary as an open source project. Since its initial release in 2010, Spark has grown to be one of the most active open source projects. Nowadays, Spark is the de facto unified engine for big data processing, data science, machine learning and data analytics workloads.
Spark SQL is the top active component in this release. 46% of the resolved tickets are for Spark SQL. These enhancements benefit all the higher-level libraries, including structured streaming and MLlib, and higher level APIs, including SQL and DataFrames. Various related optimizations are added in this release. In TPC-DS 30TB benchmark, Spark 3.0 is roughly two times faster than Spark 2.4.
Why Spark?
Scalability
Beyond OLTP: OLAP (and BI)
From Data Mining to Big Data
From Datawarehouses to Datalakes
- MapReduce
- Apache Hadoop
- Hive
- Before 2010, de facto big data SQL API
- Helped propel
Hadoopto industry

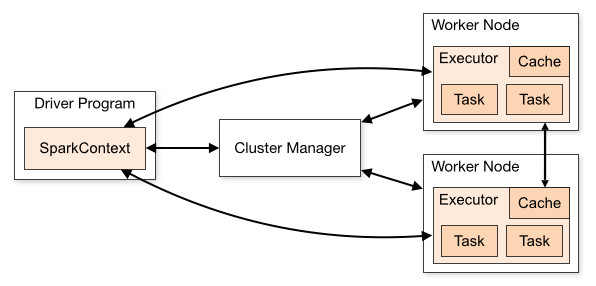
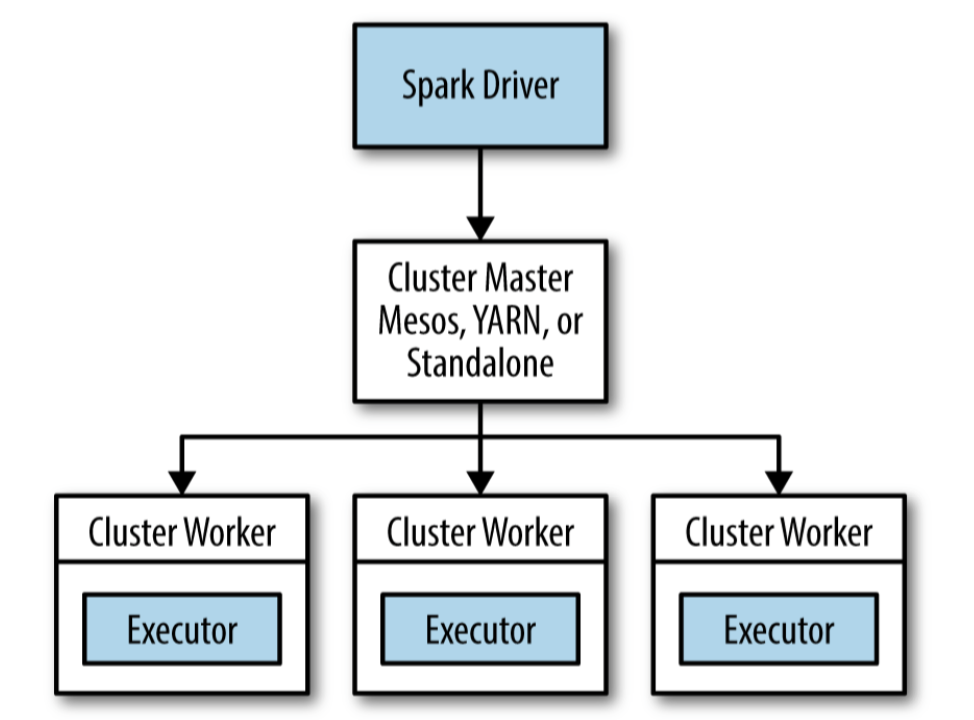
Spark organization
Note
- There is one master per cluster.
- The cluster manager/master is launched by
start-master.sh. - There are as many workers per machine on the cluster.
- A worker process is launched by
start-worker.sh(standalone mode) - Spark applications (interactive or not) exchange informations using a driver process.
- Master is per cluster, and driver is per application.
Sparksession
Spark SQL and Dataframes
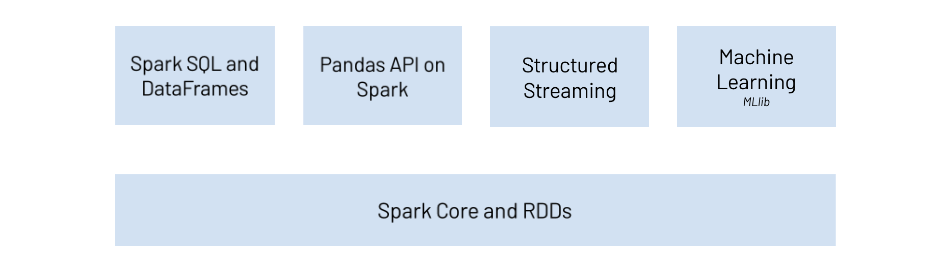
Spark core
- Implements the
RDD(Resilient Distributed Datasets)
- Spark project was launched to implement the RDD concept presented by Zaharia et al at the end of the 2000’
- In words, RDDs behave like distributed, fault-tolerant, Python collections (list or dict)
- RDDs areo immutable, they can be transformed using
maplike operations, transformed RDDs can be reduced, and the result can becollectedto the driver process
Spark SQL and HIVE (Hadoop InteractiVE)
Spark SQL relies on Hive SQL’s conventions and functions
Since release 2.0, Spark offers a native SQL parser that supports ANSI-SQL and HiveQL
Works for analysts, data engineers, data scientists
Spark-SQL is geared towards OLAP not OLTP
Rows
Spark dataframes are RDDs (collections of Rows)
from pyspark.sql import Row
row1 = Row(name="John", age=21)
row2 = Row(name="James", age=32)
row3 = Row(name="Jane", age=18)
row1['name']
rows = [row1, row2, row3]
column_names = ["Name", "Age"]
df = spark.createDataFrame(rows, column_names)
df.show()+-----+---+
| Name|Age|
+-----+---+
| John| 21|
|James| 32|
| Jane| 18|
+-----+---+
Schema
From dataframes to RDDs
(20) MapPartitionsRDD[66] at javaToPython at NativeMethodAccessorImpl.java:0 []
| MapPartitionsRDD[65] at javaToPython at NativeMethodAccessorImpl.java:0 []
| SQLExecutionRDD[64] at javaToPython at NativeMethodAccessorImpl.java:0 []
| MapPartitionsRDD[63] at javaToPython at NativeMethodAccessorImpl.java:0 []
| MapPartitionsRDD[60] at applySchemaToPythonRDD at NativeMethodAccessorImpl.java:0 []
| MapPartitionsRDD[59] at map at SerDeUtil.scala:69 []
| MapPartitionsRDD[58] at mapPartitions at SerDeUtil.scala:117 []
| PythonRDD[57] at RDD at PythonRDD.scala:53 []
| ParallelCollectionRDD[56] at readRDDFromFile at PythonRDD.scala:289 []Spark dataframe API
The Spark dataframe API offers a developper-friendly API for implementing
- Relational algebra \(\sigma, \pi, \bowtie, \cup, \cap, \setminus\)
- Partitionning
GROUP BY - Aggregation and Window functions
Compare the Spark Dataframe API with:
dplyr, dtplyr, dbplyr in R Tidyverse
Pandas
Pandas on Spark
Chaining and/or piping enable modular query construction
Basic Single Tables Operations (methods/verbs)
| Operation | Description |
|---|---|
select |
Chooses columns from the table \(\pi\) |
selectExpr |
Chooses columns and expressions from table \(\pi\) |
where |
Filters rows based on a boolean rule \(\sigma\) |
limit |
Limits the number of rows LIMIT ... |
orderBy |
Sorts the DataFrame based on one or more columns ORDER BY ... |
alias |
Changes the name of a column AS ... |
cast |
Changes the type of a column |
withColumn |
Adds a new column |
Toy example
Querying SQL style
Select
The argument of select() is *cols where cols can be built from column names (strings), column expressions like df.age + 10, lists
+----+----------+
| nom|(age + 10)|
+----+----------+
|John| 31|
|Jane| 35|
+----+----------+
Adding new columns
## In a SQL query:
query = "SELECT *, 12*age AS age_months FROM table"
## Using Spark SQL API:
df.withColumn("age_months", df.age * 12).show()
## Or
df.select("*",
(df.age * 12).alias("age_months")
).show()+----+---+------+----------+
|name|age|gender|age_months|
+----+---+------+----------+
|John| 21| male| 252|
|Jane| 25|female| 300|
+----+---+------+----------+
+----+---+------+----------+
|name|age|gender|age_months|
+----+---+------+----------+
|John| 21| male| 252|
|Jane| 25|female| 300|
+----+---+------+----------+
Basic operations
The full list of operations that can be applied to a
DataFramecan be found in the [DataFrame doc]The list of operations on columns can be found in the [Column docs]
Spark APIs for R
sparkR and sparklyr
sparkRis the official Spark API forRusers
sparklyr(released 2016) is the de facto Spark API fortidyverse
A glimpse at Sparklyr
Spark dataframes can be handled through dplyr pipelines
# Source: spark<?> [?? x 4]
# Groups: Insul
# Ordered by: Insul, Temp
Insul Temp Gas Fn
<chr> <dbl> <dbl> <dbl>
1 After -0.7 4.8 0.0333
2 After 0.8 4.6 0.0667
3 After 1 4.7 0.1
4 After 1.4 4 0.133
5 After 1.5 4.2 0.167
6 After 1.6 4.2 0.2
7 After 2.3 4.1 0.233
8 After 2.5 4 0.3
9 After 2.5 3.5 0.3
10 After 3.1 3.2 0.333
# ℹ more rows
# ℹ Use `print(n = ...)` to see more rowsUnder the hood
<SQL>
SELECT PERCENTILE_CONT(0.25) WITHIN GROUP (ORDER BY `Temp`) AS `x`
FROM `whiteside`dplyr queries are translated into Spark/Hive SQL
quantile() is a base R function, it is matched to the Spark/Hive percentile() function
sparklyr aims at avoiding sending R functions/objects across the cluster
In words
…
sparklyrtranslatesdplyrfunctions such asarrangeinto a SQL query plan that is used by SparkSQL. This is not the case withSparkR, which has functions for SparkSQL tables and Spark DataFrames.
… Databricks does not recommended combining
SparkRandsparklyrAPIs in the same script, notebook, or job.
Pandas Spark API
Apache Spark includes Arrow-optimized execution of Python logic in the form of
pandasfunction APIs, which allow users to applypandastransformations directly to PySpark DataFrames. Apache Spark also supportspandasUDFs, which use similar Arrow-optimizations for arbitrary user functions defined in Python.