Technologies Big Data
Master I MIDS & Informatique
2024-02-19
Main file formats


 ]
]
We shall talk about the core concepts and use-cases for the following popular data formats:
Avro: https://avro.apache.orgParquet: https://orc.apache.org
Avro: Principles
Avrois a row-based data format and data serialization system released by theHadoopworking group in 2009Data schema is stored as
JSONin the header. Rest of the data stored in a binary format to make it compact and efficientAvrois language-neutral and can be used by many languages (for nowC,C++,...,Python, andR)One shining point of
Avro: robust support for schema evolution
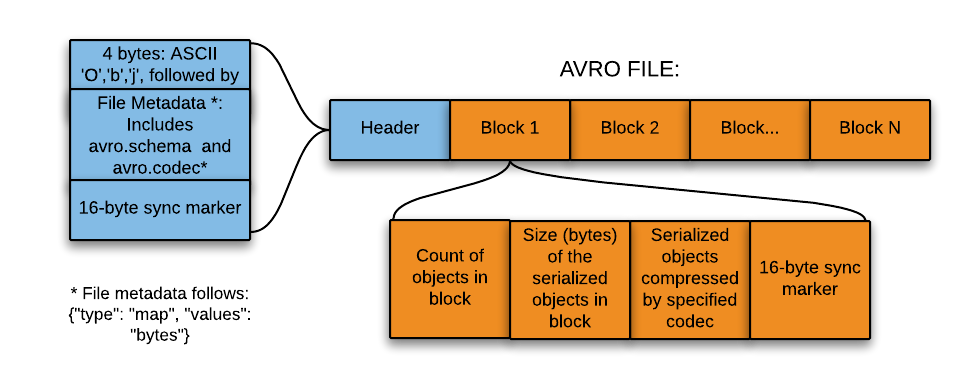
Avro: organization
Parquet: History and Principles
Parquetis an open-source file format forHadoopcreated byClouderaandTwitterin 2013It stores nested data structures in a flat columnar format.
Compared to traditional row-oriented approaches,
Parquetis more efficient in terms of storage and performanceIt is especially good for queries that need read a small subset of columns from a data file with many columns : only the required columns are read (optimized I/O)
Parquet: organization (continued)
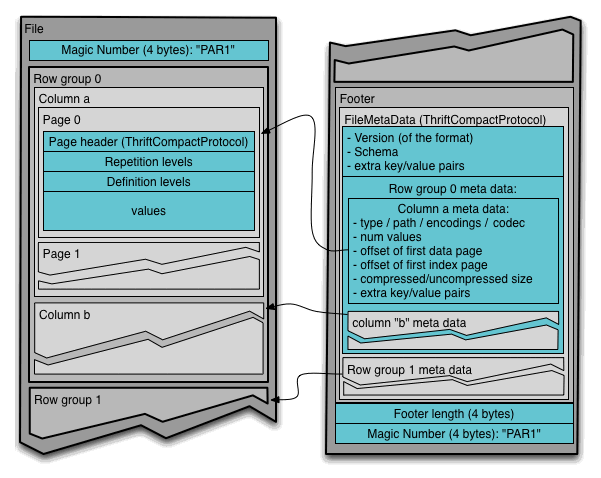
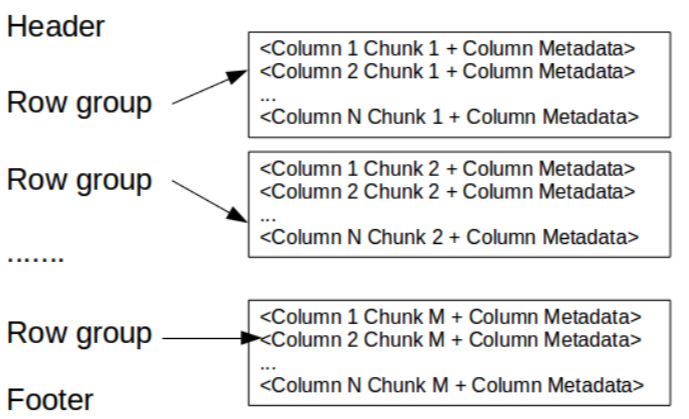
About Parquet
ORC: principles
ORCstands for Optimized Row Columnar file format. Created by Hortonworks in 2013 in order to speed upHiveORCfile format provides a highly efficient way to store dataIt is a raw columnar data format highly optimized for reading, writing, and processing data in
HiveIt stores data in a compact way and enables skipping quickly irrelevant parts
About ORC (onctinued)
Index data include min and max values for each column and the row’s positions within each column
ORCindexes are used only for the selection of stripes and row groups and not for answering queries

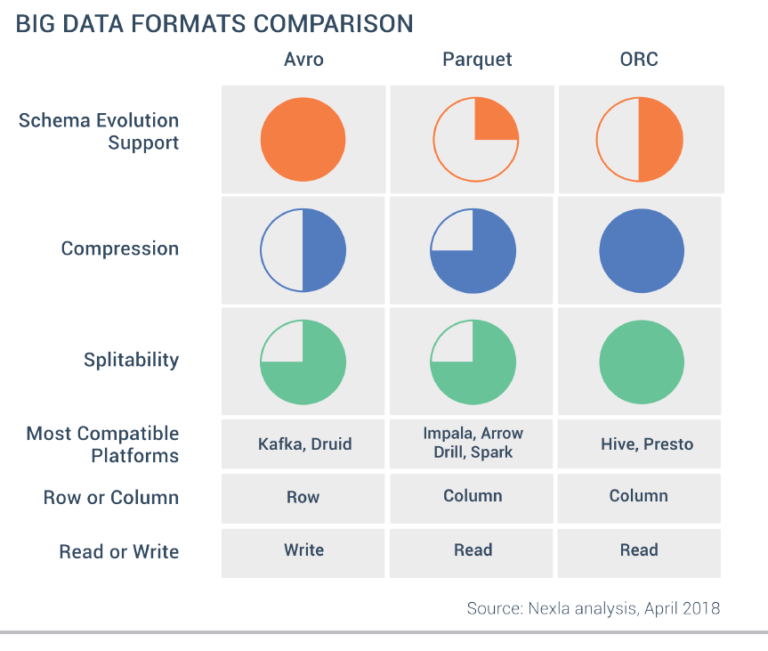
In summary…
Thank you !
![]()