Data preprocessing and visualisation of a credit scoring dataset
Published
February 7, 2024
We’ll work on a dataset gro.csv for credit scoring that was proposed some years ago as a data challenge on some data challenge website.
It is a realistic and messy dataset with a lot of missing values, several types (date, categorical, numeric) of features, so that serious data cleaning and formating is required.
This dataset contains the following columns:
Column name
Description
BirthDate
Date of birth of the client
Customer_Open_Date
Creation date of the client’s first account at the bank
Customer_Type
Type of client (existing / new)
Educational_Level
Highest diploma
Id_Customer
Id of the client
Marital_Status
Family situation
Nb_Of_Products
Number of products held by the client
Net_Annual_Income
Annual revenue
Number_Of_Dependant
Number of dependents
P_Client
Non-disclosed feature
Prod_Category
Product category
Prod_Closed_Date
Closing date of the last product
Prod_Decision_Date
Decision date of the last agreement for a financing product
Prod_Sub_Category
Sub-category of the product
Source
Financing source (Branch or Sales)
Type_Of_Residence
Residential situation
Y
Credit was granted (yes / no)
Years_At_Business
Number of year at the current job position
Years_At_Residence
Number of year at the current housing
Your job
Read and explore the gro.csv dataset using pandas, matplotlib, seaborn, and plotly.
The column separator in the CSV file is not , but ; so you need to use the sep option in pd.read_csv
The categorical columns must be imported as category type (not object)
Something weird is going on with the Net_Annual_Income column… Try to understand what is going on and try to fix it
Several columns are empty, we need to remove them (or not even read them)
Dates must be imported as dates and not strings
Remove rows with missing values
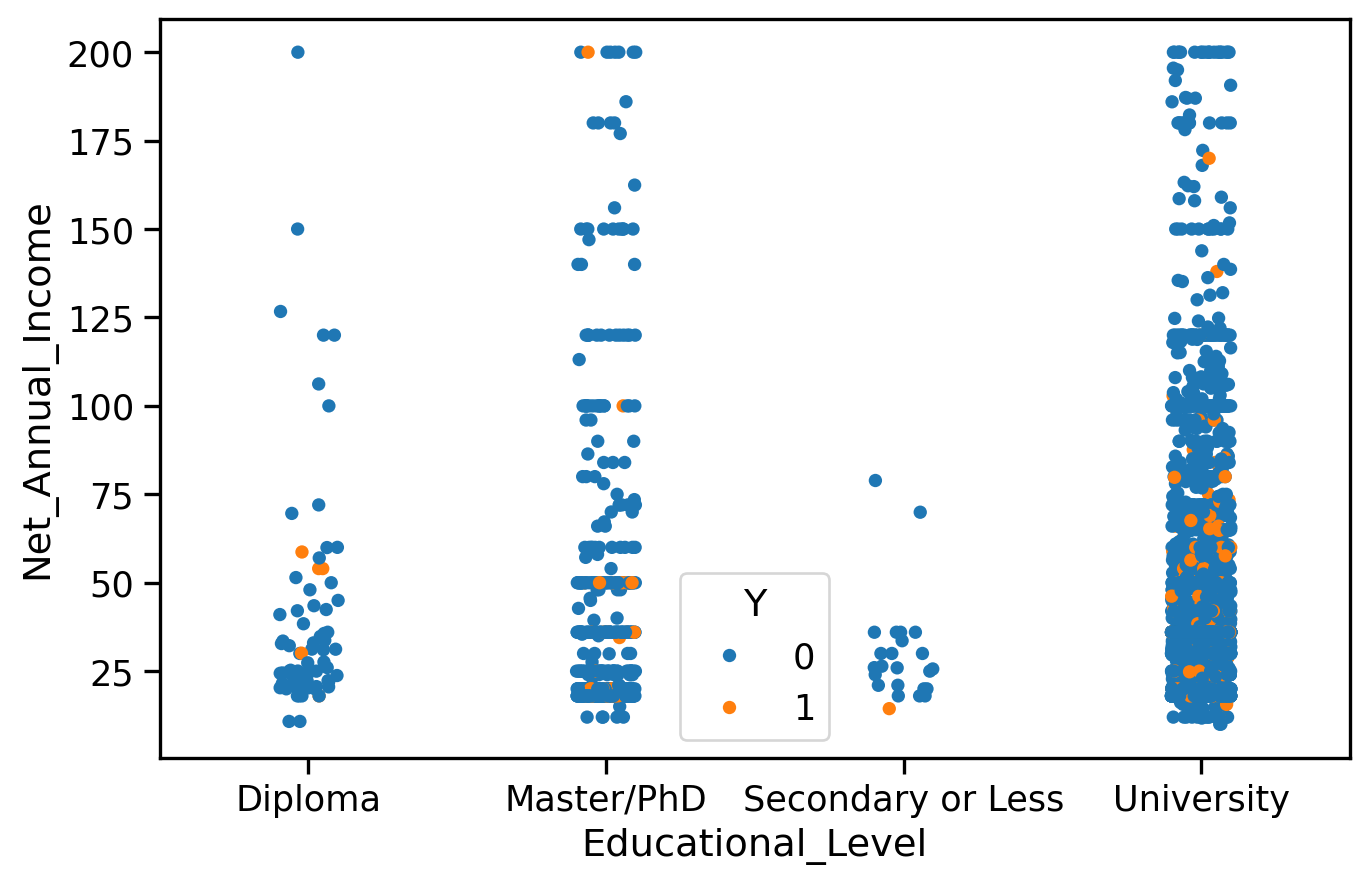
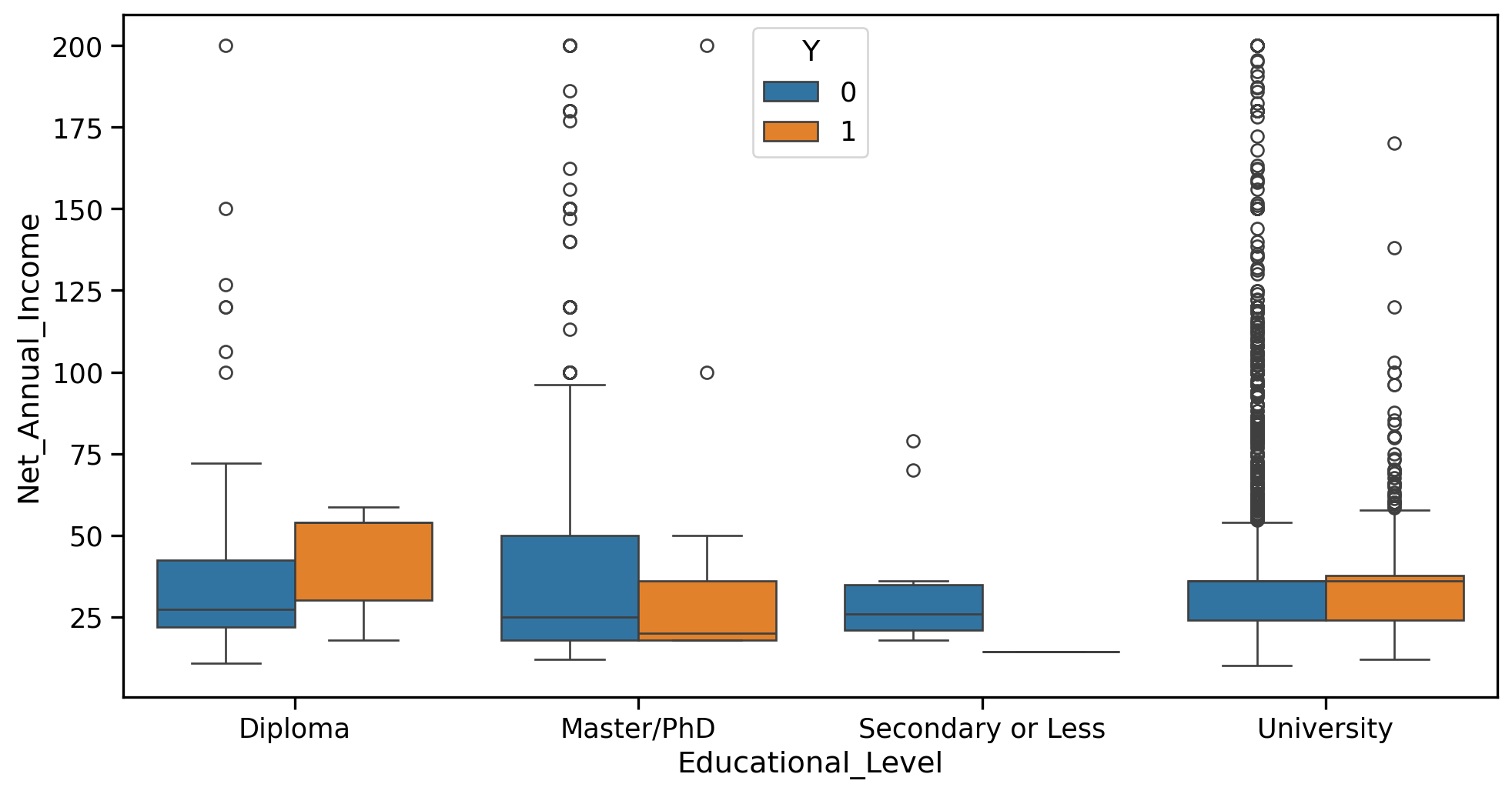
Many of these things can be done right at the beginning, when reading the CSV file, through some options to the pd.read_csv() function. You might need to read carefully its documentation in order to see which options are useful. Once you are happy with your importation and cleaning of the data, you can: - Use pandas and some graphical backend to perform data visualization … - … in order to understand visually the impact of some features on Y (credit was granted or not). For this, you need to decide which plots make sense for this and produce them
We will provide thorough explanations and code that performs all of this in subsequent sessions.
A quick and dirty import
Let’s import the data into a pandas dataframe, as simply as possible The only thing we care about for now is the fact that the column separator is ';' and not ',' (American csv files use , as a default separator, Continental European csv files use ;).
import requestsimport os# The path containing your notebookpath_data ='./'# The name of the filefilename ='gro.csv.gz'# the file pathfpath = os.path.join(path_data, filename)if os.path.exists(fpath):print(f'The file "{fpath}" already exists.')else: url ='https://stephane-v-boucheron.fr/data/gro.csv.gz' r = requests.get(url)withopen(fpath, 'wb') as f: f.write(r.content)print(f'Downloaded file "{fpath}".')
The file "./gro.csv.gz" already exists.
import numpy as npimport pandas as pdimport plotly.express as pximport matplotlib.pyplot as pltimport seaborn as snsfrom pandas import Timestampimport pickle as pkl
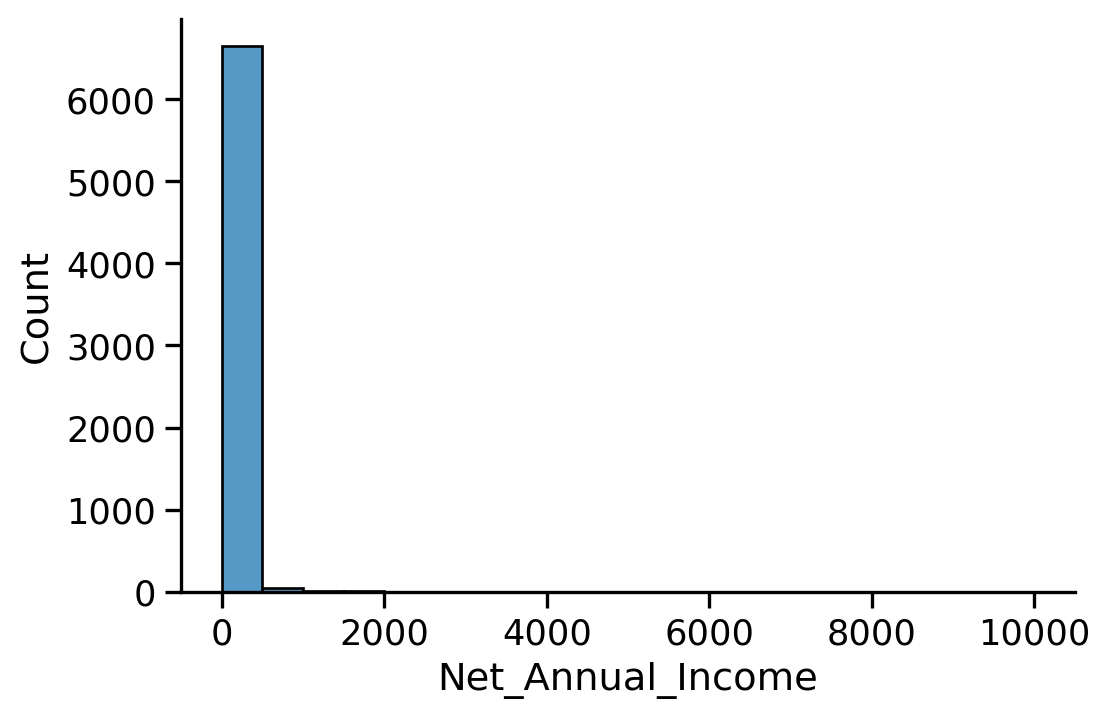
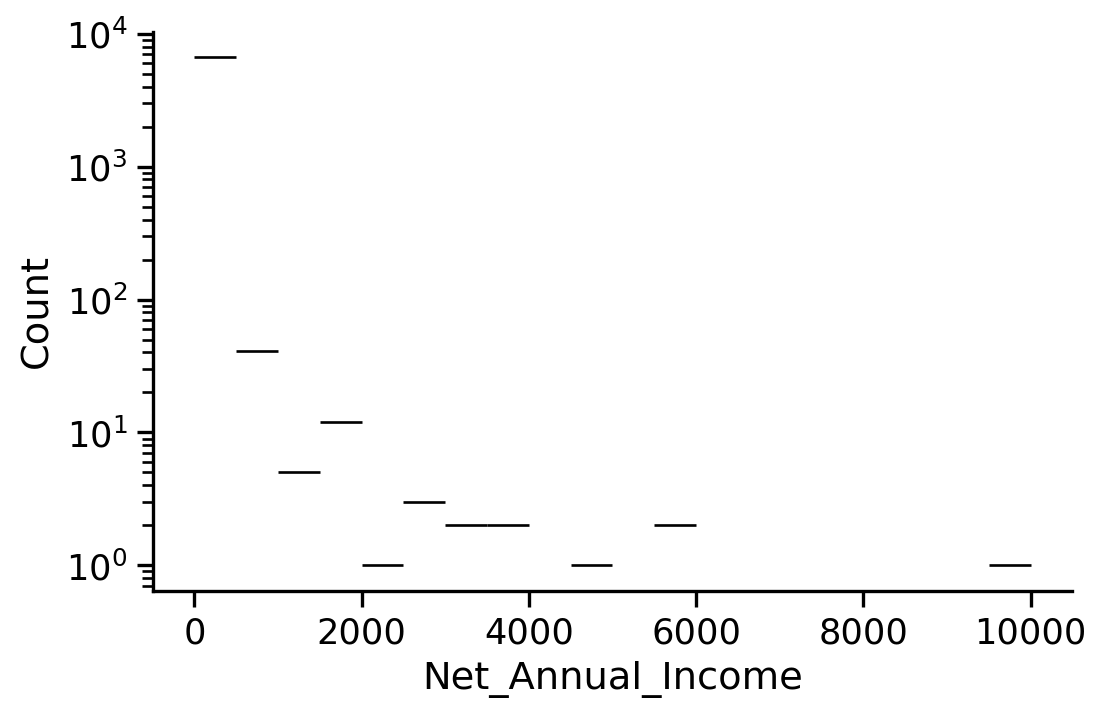
Net actual income is a string as well ! While it is clearly a number !!!
df.describe(include='all')
Id_Customer
Y
Customer_Type
BirthDate
Customer_Open_Date
P_Client
Educational_Level
Marital_Status
Number_Of_Dependant
Years_At_Residence
...
Prod_Sub_Category
Prod_Decision_Date
Source
Type_Of_Residence
Nb_Of_Products
Prod_Closed_Date
Prod_Category
Unnamed: 19
Unnamed: 20
Unnamed: 21
count
6725.000000
6725.000000
6725
6725
6725
6725
6725
6725
6723.000000
6725.000000
...
6725
6725
6725
6725
6725.000000
1434
6725
0.0
0.0
0.0
unique
NaN
NaN
2
5224
1371
2
4
5
NaN
NaN
...
3
278
2
5
NaN
349
13
NaN
NaN
NaN
top
NaN
NaN
Non Existing Client
01/10/1984
12/12/2011
NP_Client
University
Married
NaN
NaN
...
C
06/12/2011
Sales
Owned
NaN
30/05/2013
B
NaN
NaN
NaN
freq
NaN
NaN
4214
8
50
6213
5981
5268
NaN
NaN
...
5783
58
5149
5986
NaN
116
3979
NaN
NaN
NaN
mean
4821.029740
0.072862
NaN
NaN
NaN
NaN
NaN
NaN
1.051614
12.564758
...
NaN
NaN
NaN
NaN
1.086840
NaN
NaN
NaN
NaN
NaN
std
2775.505395
0.259930
NaN
NaN
NaN
NaN
NaN
NaN
1.332712
9.986257
...
NaN
NaN
NaN
NaN
0.295033
NaN
NaN
NaN
NaN
NaN
min
1.000000
0.000000
NaN
NaN
NaN
NaN
NaN
NaN
0.000000
0.000000
...
NaN
NaN
NaN
NaN
1.000000
NaN
NaN
NaN
NaN
NaN
25%
2399.000000
0.000000
NaN
NaN
NaN
NaN
NaN
NaN
0.000000
4.000000
...
NaN
NaN
NaN
NaN
1.000000
NaN
NaN
NaN
NaN
NaN
50%
4822.000000
0.000000
NaN
NaN
NaN
NaN
NaN
NaN
0.000000
10.000000
...
NaN
NaN
NaN
NaN
1.000000
NaN
NaN
NaN
NaN
NaN
75%
7209.000000
0.000000
NaN
NaN
NaN
NaN
NaN
NaN
2.000000
17.000000
...
NaN
NaN
NaN
NaN
1.000000
NaN
NaN
NaN
NaN
NaN
max
9605.000000
1.000000
NaN
NaN
NaN
NaN
NaN
NaN
20.000000
73.000000
...
NaN
NaN
NaN
NaN
3.000000
NaN
NaN
NaN
NaN
NaN
11 rows × 22 columns
Method describe() delivers a summary for numerical columns. It provides location parameters (mean and median) and scale parameters (standard deviation and Inter Quartile Range (IQR)). For other types of columns it is useless.
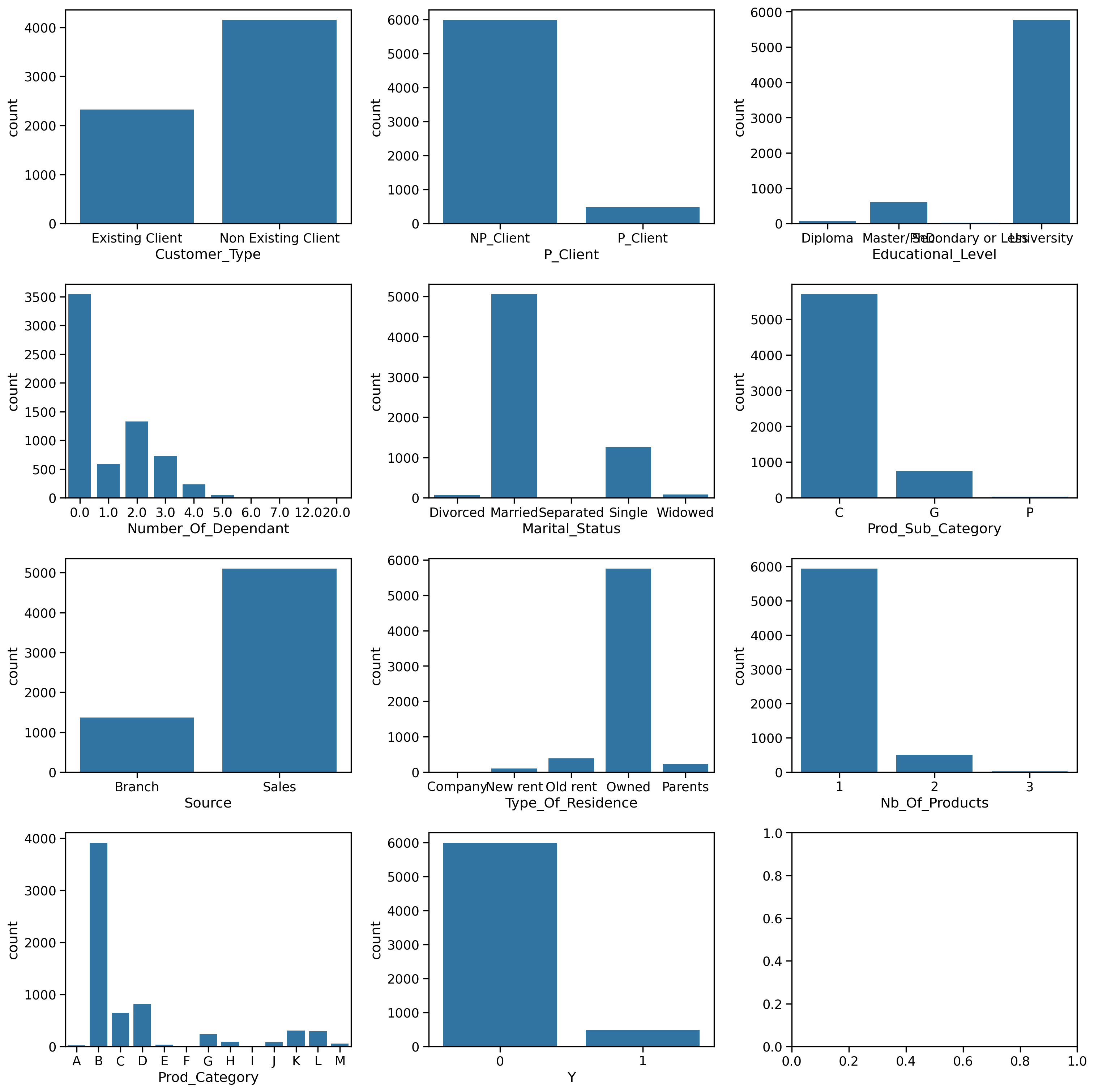
By looking at column names, column descriptions, and common sense, we can infer the type of features we face. There are dates features, numerical features, and categorical features. Some features can be either treated as categorical or numerical.
There are many missing values, that need to be handled.
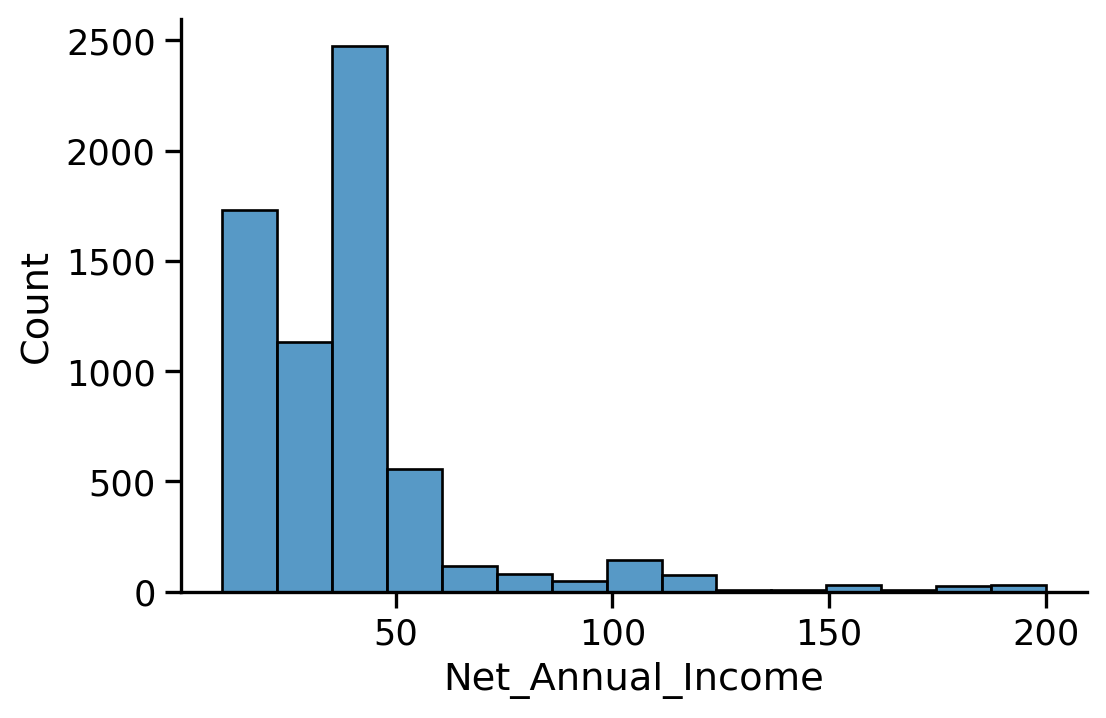
The annual net income is imported as a string, why?
Dates should be handled as dates and not as strings: this allows us to use the date and time processing functions from the datetime package.
Here is a tentative structure of the features
Numerical features
Years_At_Residence
Net_Annual_Income
Years_At_Business
Features to be decided
Number_Of_Dependant
Nb_Of_Products
Categorical features
Customer_Type
P_Client
Educational_Level
Marital_Status
Prod_Sub_Category
Source
Type_Of_Residence
Prod_Category
Date features
BirthDate
Customer_Open_Date
Prod_Decision_Date
Prod_Closed_Date
A closer look at the import problems
Let us find solutions to all these import problems.
The last three columns are empty
It seems to come from the fact that the data always ends with several ';' characters. We can remove them simply using the usecols option from read_csv.
Passing how=“all” to method dropna() (df.dropna(how="all")) will drop only rows that are all NA:
We need to specify which columns must be encoded as dates using the parse_dates option from read_csv. Fortunately enough, pandas is clever enough to interpret the date format.
type(df.loc[0, 'BirthDate'])
str
There is a lot of missing values
We will see below that a single column contains most missing values.
We need to say the dtype we want to use for some columns using the dtype option of read_csv.
type(df.loc[0, 'Prod_Sub_Category'])
str
df['Prod_Sub_Category'].unique()
array(['C', 'G', 'P'], dtype=object)
The annual net income is imported as a string
This problem comes from the fact that the decimal separator is in continental European notation: it’s a ',' and not a '.', so we need to specify it using the decimal option to read_csv.
We build a dict that specifies the dtype to use for each column and pass it to read_csv() using the dtype option
We also specify the decimal, usecols and parse_dates options
Note
Some columns could be imported as int.
However, pandas is built above numpy, pandas does not support columns with integer dtype and missing values.
As columnn type inference does not work universally, a safeguard consists in providing read_csv() with optinal argument dtype. The default value is None. The default value is overriden by a dictionary where keys are strings denoting the column names where type inference is not satisfactory and values denote the desired types.
Note that the intended type is 'category', the function still has to infer the categories from the data, and to build the actual categorical type with a proper encoding.
We can use the dictionary unpacking capabilities of Python to save the overriden keyword parameters into a dictionary. The dictionary can be serialized and saved on disc. It is then considered as metadat.
gro_read_spec_dict = {'sep': ';', # continental separator'decimal': ',', # continental decimal separator'usecols': range(19), # Range of the columns to keep (remove the last three ones)'parse_dates': ['BirthDate', # Which columns should be parsed as dates ?'Customer_Open_Date', 'Prod_Decision_Date', 'Prod_Closed_Date'],'dtype': gro_dtypes # Specify some dtypes }
Using the metadata packed into the dictionary turns easy and concise. The same metadata can be reused for any csv file with the same features.
/tmp/ipykernel_14457/1983308737.py:1: UserWarning:
Parsing dates in %d/%m/%Y format when dayfirst=False (the default) was specified. Pass `dayfirst=True` or specify a format to silence this warning.
/tmp/ipykernel_14457/1983308737.py:1: UserWarning:
Parsing dates in %d/%m/%Y format when dayfirst=False (the default) was specified. Pass `dayfirst=True` or specify a format to silence this warning.
/tmp/ipykernel_14457/1983308737.py:1: UserWarning:
Parsing dates in %d/%m/%Y format when dayfirst=False (the default) was specified. Pass `dayfirst=True` or specify a format to silence this warning.
Column BirthDate is meant to be a date column. Nevertheless, is is not converted to a date or datetime column.
If a column or index cannot be represented as an array of datetime, say because of an unparsable value or a mixture of timezones, the column or index will be returned unaltered as an object data type. For non-standard datetime parsing, use to_datetime() after read_csv().
If we do not set optional arguments, pd.to_datetime() fails to convert df['BirthDate'].
bd = pd.to_datetime(df['BirthDate'])
We get a message:
ValueError: time data “13/06/1974” doesn’t match format “%m/%d/%Y”, at position 2. You might want to try: - passing format if your strings have a consistent format; - passing format='ISO8601' if your strings are all ISO8601 but not necessarily in exactly the same format; - passing format='mixed', and the format will be inferred for each element individually. You might want to use dayfirst alongside this.
Indeed, the format of the first items in column BirthDate seems to be %d/%m/%Y (as for the other date columns).
An easy fix consists in setting optional argument dayfirst to True.
/tmp/ipykernel_14457/1697804417.py:6: FutureWarning:
The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
income_category
#customers
%cummulative clients
228
36.000000
2265
0.337254
31
18.000000
1087
0.499107
43
20.000000
538
0.579214
156
30.000000
506
0.654556
318
50.000000
317
0.701757
98
25.000000
314
0.748511
481
100.000000
109
0.764741
84
24.000000
101
0.779780
370
60.000000
95
0.793925
518
120.000000
57
0.802412
267
42.000000
44
0.808964
416
72.000000
40
0.814920
309
48.000000
36
0.820280
562
200.000000
29
0.824598
253
40.000000
25
0.828320
440
80.000000
25
0.832043
536
150.000000
23
0.835468
20
12.000000
22
0.838743
573
250.000000
22
0.842019
598
500.000000
21
0.845146
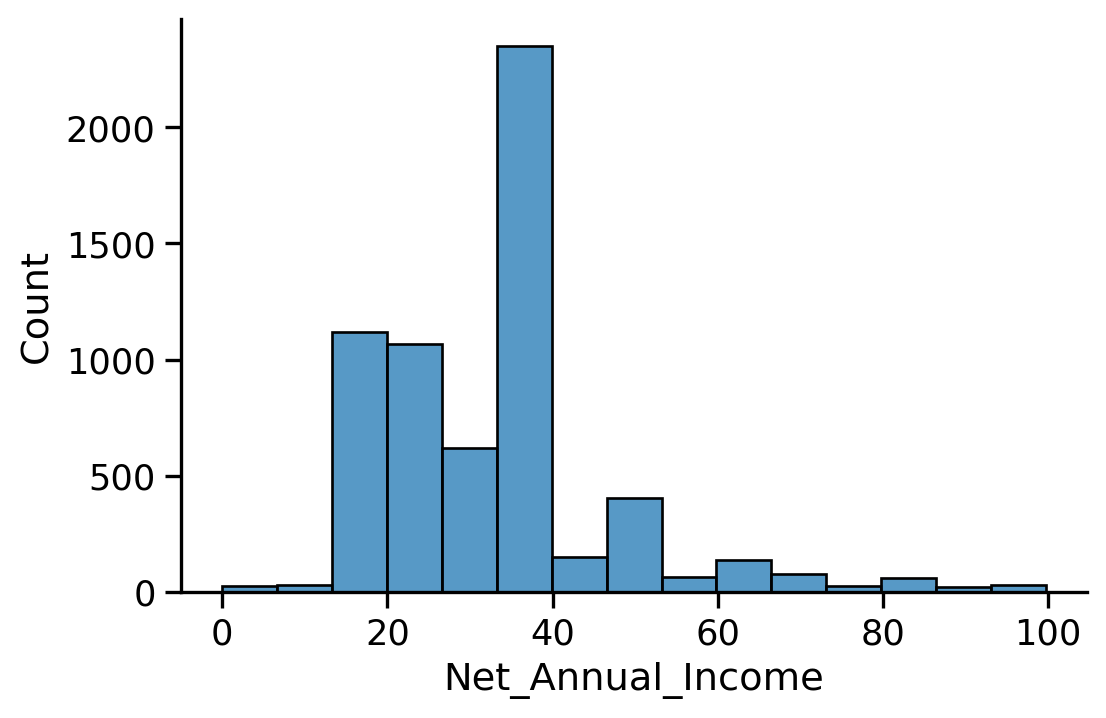
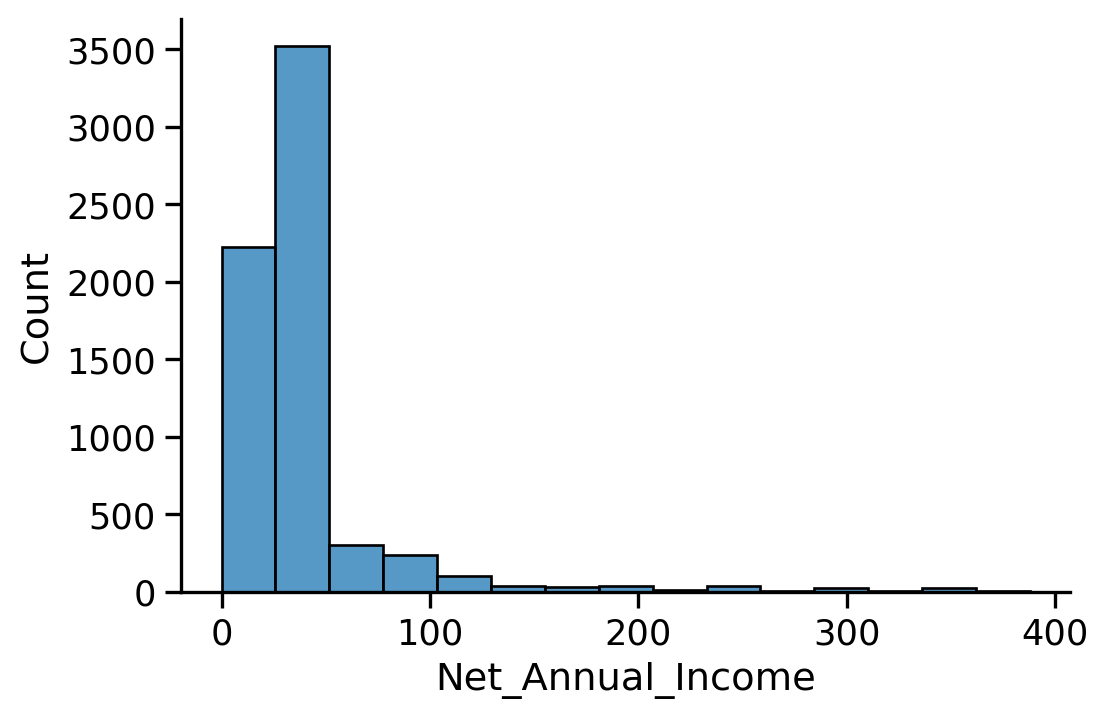
We have some overrepresented values (many possible explanations for this)
To clean the data, we can, for instance, keep only the revenues between [10, 200], or leave it as such
# First we make lists of continuous, categorial and date featurescnt_featnames = ['Years_At_Residence','Net_Annual_Income','Years_At_Business','Number_Of_Dependant']cat_featnames = ['Customer_Type','P_Client','Educational_Level','Marital_Status','Prod_Sub_Category','Source','Type_Of_Residence','Prod_Category','Nb_Of_Products']date_featnames = ['BirthDate','Customer_Open_Date','Prod_Decision_Date'#'Prod_Closed_Date']
We removed rows that contained missing values. The index of the dataframe is therefore not contiguous anymore
all_features.index.max()
6715
This could be a problem for later. So let’s reset the index to get a contiguous one
all_features.shape
(6473, 36)
all_features.reset_index(inplace=True, drop=True)
Note
Why does the index matter?
For example, when adding a new column to a dataframe, only items from the new series that have a corresponding index in the Dataframe will be added. The receiving dataframe is not extended to accomodate the new series.
all_features.head()
Nb_Of_Products
Customer_Type#Non Existing Client
P_Client#P_Client
Educational_Level#Master/PhD
Educational_Level#Secondary or Less
Educational_Level#University
Marital_Status#Married
Marital_Status#Separated
Marital_Status#Single
Marital_Status#Widowed
...
Prod_Category#K
Prod_Category#L
Prod_Category#M
Years_At_Residence
Net_Annual_Income
Years_At_Business
Number_Of_Dependant
BirthDate
Customer_Open_Date
Prod_Decision_Date
0
1
True
False
False
False
True
True
False
False
False
...
False
False
False
10
36.0
3.0
3.0
19149
4401
4396
1
1
True
False
False
False
True
True
False
False
False
...
False
False
False
1
36.0
1.0
3.0
16983
4375
4374
2
1
False
True
False
False
True
True
False
False
False
...
False
False
False
12
18.0
2.0
0.0
18134
5479
4603
3
1
True
False
False
False
True
True
False
False
False
...
False
False
False
10
36.0
1.0
2.0
18352
4325
4324
4
1
False
False
False
False
True
True
False
False
False
...
False
True
False
3
36.0
1.0
3.0
15187
4547
4534
5 rows × 36 columns
Let’s save the data using pickle
X = all_featuresy = df['Y']# Let's put eveything in a dictionarydf_pkl = {}# The features and the labelsdf_pkl['features'] = Xdf_pkl['labels'] = y# And also the list of columns we built abovedf_pkl['cnt_featnames'] = cnt_featnamesdf_pkl['cat_featnames'] = cat_featnamesdf_pkl['date_featnames'] = date_featnameswithopen("gro_training.pkl", 'wb') as f: pkl.dump(df_pkl, f)
/home/boucheron/.local/lib/python3.10/site-packages/plotly/express/_core.py:2065: FutureWarning:
When grouping with a length-1 list-like, you will need to pass a length-1 tuple to get_group in a future version of pandas. Pass `(name,)` instead of `name` to silence this warning.
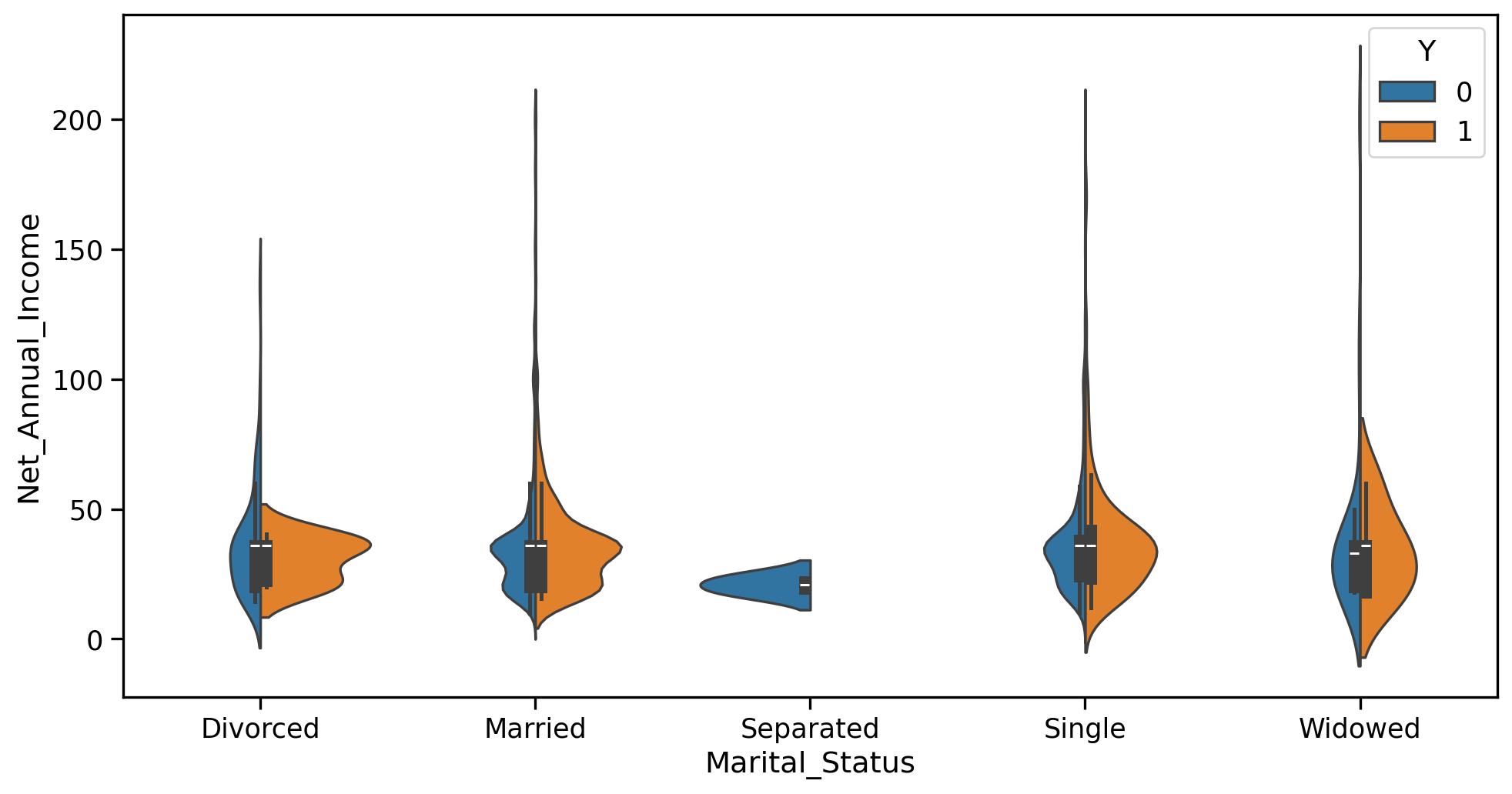
s = df['Marital_Status'].value_counts()df_counts = pd.DataFrame({'status': s.index.to_list(),'count': s.to_list()})
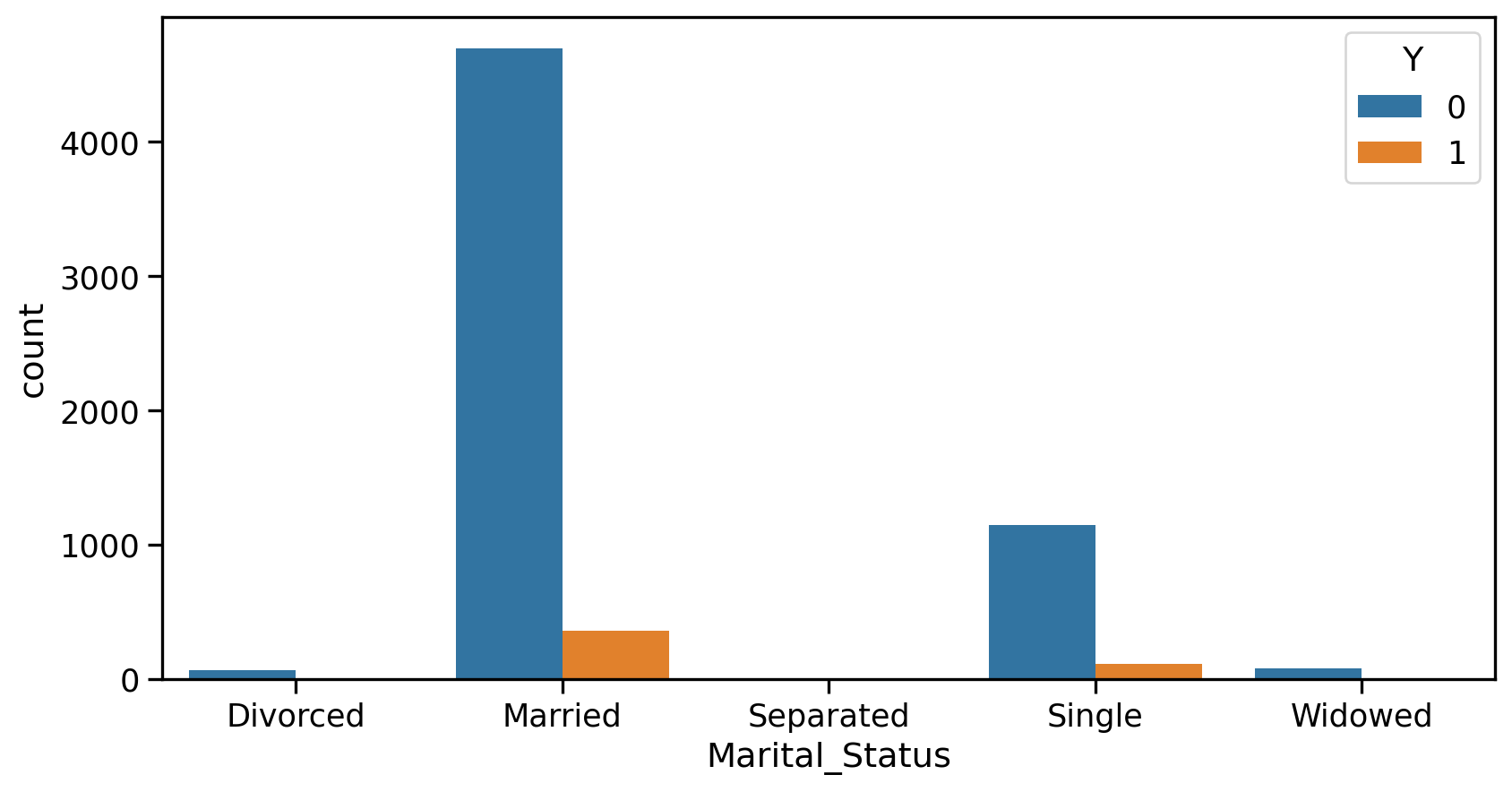
Comment on file formats
You can use other methods starting with
.to_XXto save in another format.csvfor “small” datasets (several MB). But this is not a self-documented format.picklefor more compressed and faster format (limited to 4GB). It’s the standard binary serialization format ofPythonfeatheris another fast and lightweight file format for storing data frames. A very popular exchange format.parquetis a format for big distributed data (works nicely withSpark)among several others…
Have a look at the
PyArrowpackageAnd you can read again using the corresponding
read_XXfunction