print("Salut tout le monde!")Salut tout le monde!We introduce here the python language. Only the bare minimum necessary for getting started with the data-science stack (a bunch of libraries for data science). Python is a programming language, as are C++, java, fortran, javascript, etc.
an interpreted (as opposed to compiled) language. Contrary to e.g. C++ or fortran, one does not compile Python code before executing it.
Used as a scripting language, by python python script.py in a terminal
But can be used also interactively: the jupyter notebook, iPython, etc.
A free software released under an open-source license: Python can be used and distributed free of charge, even for building commercial software.
multi-platform: Python is available for all major operating systems, Windows, Linux/Unix, MacOS X, most likely your mobile phone OS, etc.
A very readable language with clear non-verbose syntax
A language for which a large amount of high-quality packages are available for various applications, including web-frameworks and scientific computing
It has been one of the top languages for data science and machine learning for several years, because it is expressive and and easy to deploy
An object-oriented language
See https://www.python.org/about/ for more information about distinguishing features of Python.
Simple answer: don’t use Python 2, use Python 3
Python 2 is mostly deprecated and has not been maintained for years
You’ll end up hanged if you use Python 2
If Python 2 is mandatory at your workplace, find another work
In a jupyter notebook, you have an interactive interpreter.
You type in the code cells, execute commands with Shift + Enter (on MacOS)
print("Salut tout le monde!")Salut tout le monde!1 + 4243type(1+1)intWe can assign values to variables with =
a = (3 + 5 ** 2) % 4
a0We don’t declare the type of a variable before assigning its value. In C, conversely, one should write
int a = 4;or even
int a ;
...
a = 4 ;17 ** 5428004153099680695240677662228684856314409365427758266999205063931175132640587226837141154215226851187899067565063096026317140186260836873939218139105634817684999348008544433671366043519135008200013865245747791955240844192282274023825424476387832943666754140847806277355805648624376507618604963106833797989037967001806494232055319953368448928268857747779203073913941756270620192860844700087001827697624308861431399538404552468712313829522630577767817531374612262253499813723569981496051353450351968993644643291035336065584116155321928452618573467361004489993801594806505273806498684433633838323916674207622468268867047187858269410016150838175127772100983052010703525089There exists a floating point type that is created when the variable has decimal values
c = 2.type(c)floatc = 2
type(c)inttruc = 1 / 2
truc0.51 // 2 + 1 % 21type(truc)floatSimilarly, boolean types are created from a comparison
test = 3 > 4
testFalsetype(test)boolFalse == (not True)True1.41 < 2.71 and 2.71 < 3.14True# It's equivalent to
1.41 < 2.71 < 3.14Truea = 1
type(a)intb = float(a)
type(b)floatstr(b)'1.0'bool(b)
# All non-zero, non empty objects are casted to boolean as True (more later)Truebool(1-1)FalsePython provides many efficient types of containers, in which collections of objects can be stored.
The main ones are list, tuple, set and dict (but there are many others…)
tt = 'truc', 3.14, "truc"
tt('truc', 3.14, 'truc')tt[0]'truc'You can’t change a tuple, we say that it’s immutable
tt[0] = 1Three ways of doing the same thing
# Method 1
tuple([1, 2, 3])(1, 2, 3)# Method 2
1, 2, 3(1, 2, 3)# Method 3
(1, 2, 3)(1, 2, 3)Simpler is better in Python, so usually you want to use Method 2.
toto = 1, 2, 3
toto(1, 2, 3)import thisThe Zen of Python, by Tim Peters
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
Complex is better than complicated.
Flat is better than nested.
Sparse is better than dense.
Readability counts.
Special cases aren't special enough to break the rules.
Although practicality beats purity.
Errors should never pass silently.
Unless explicitly silenced.
In the face of ambiguity, refuse the temptation to guess.
There should be one-- and preferably only one --obvious way to do it.
Although that way may not be obvious at first unless you're Dutch.
Now is better than never.
Although never is often better than *right* now.
If the implementation is hard to explain, it's a bad idea.
If the implementation is easy to explain, it may be a good idea.
Namespaces are one honking great idea -- let's do more of those!A list is an ordered collection of objects. These objects may have different types. For example:
colors = ['red', 'blue', 'green', 'black', 'white']colors[0]'red'type(colors)listIndexing: accessing individual objects contained in the list
colors[2]'green'colors[2] = 3.14
colors['red', 'blue', 3.14, 'black', 'white']Warning. Indexing starts at 0 (as in C), not at 1 (as in Fortran, R, or Matlab) for any iterable object in Python.
Counting from the end with negative indices:
colors[-1]'white'Index must remain in the range of the list
colors[10]colors['red', 'blue', 3.14, 'black', 'white']tt('truc', 3.14, 'truc')colors.append(tt)
colors['red', 'blue', 3.14, 'black', 'white', ('truc', 3.14, 'truc')]len(colors)6len(tt)3This work with anything iterable whenever it makes sense (list, str, tuple, etc.)
colors['red', 'blue', 3.14, 'black', 'white', ('truc', 3.14, 'truc')]list(reversed(colors))[('truc', 3.14, 'truc'), 'white', 'black', 3.14, 'blue', 'red']colors[::-1][('truc', 3.14, 'truc'), 'white', 'black', 3.14, 'blue', 'red']Slicing syntax: colors[start:stop:stride]
NB: All slicing parameters are optional
print(slice(4))
print(slice(1,5))
print(slice(None,13,3))slice(None, 4, None)
slice(1, 5, None)
slice(None, 13, 3)sl = slice(1,5,2)
colors[sl]['blue', 'black']colors['red', 'blue', 3.14, 'black', 'white', ('truc', 3.14, 'truc')]colors[3:]['black', 'white', ('truc', 3.14, 'truc')]colors[:3]['red', 'blue', 3.14]colors[1::2]['blue', 'black', ('truc', 3.14, 'truc')]colors[::-1][('truc', 3.14, 'truc'), 'white', 'black', 3.14, 'blue', 'red']Different string syntaxes (simple, double or triple quotes):
s = 'tintin'
type(s)strs'tintin's = """ Bonjour,
Je m'appelle Stephane.
Je vous souhaite une bonne journée.
Salut.
"""
s" Bonjour,\nJe m'appelle Stephane.\nJe vous souhaite une bonne journée.\nSalut. \n"s.strip()"Bonjour,\nJe m'appelle Stephane.\nJe vous souhaite une bonne journée.\nSalut."print(s.strip())Bonjour,
Je m'appelle Stephane.
Je vous souhaite une bonne journée.
Salut.len(s)91# Casting to a list
list(s.strip()[:15])['B', 'o', 'n', 'j', 'o', 'u', 'r', ',', '\n', 'J', 'e', ' ', 'm', "'", 'a']# Arithmetics
print('Bonjour' * 2)
print('Hello' + ' all')BonjourBonjour
Hello allsss = 'A'
sss += 'bc'
sss += 'dE'
sss.lower()'abcde'ss = s.strip()
print(ss[:10] + ss[24:28])Bonjour,
Jephas.strip()"Bonjour,\nJe m'appelle Stephane.\nJe vous souhaite une bonne journée.\nSalut."s.strip().split('\n')['Bonjour,',
"Je m'appelle Stephane.",
'Je vous souhaite une bonne journée.',
'Salut.']s[::3]' BjrJmpl ea.eo ui eoeon.at \n's[3:10]' B'" ".join(['Il', 'fait', 'super', 'beau', "aujourd'hui"])"Il fait super beau aujourd'hui"Chaining method calls is the basic of pipeline building.
(
" ".join(['Il', 'fait', 'super', 'beau', "aujourd'hui"])
.title()
.replace(' ', '')
.replace("'","")
)'IlFaitSuperBeauAujourdHui'A string is immutable !!
s = 'I am an immutable guy's[2] = 's'id(s)140142340684448print(s + ' for sure')
id(s), id(s + ' for sure')I am an immutable guy for sure(140142340684448, 140143828474960)'square of 2 is ' + str(2 ** 2)'square of 2 is 4''square of 2 is %d' % 2 ** 2'square of 2 is 4''square of 2 is {}'.format(2 ** 2)'square of 2 is 4''square of 2 is {square}'.format(square=2 ** 2)'square of 2 is 4'# And since Python 3.6 you can use an `f-string`
number = 2
square = number ** 2
f'square of {number} is {square}''square of 2 is 4'in keywordYou can use the in keyword with any container, whenever it makes sense
print(s)
print('Salut' in s)I am an immutable guy
Falseprint(tt)
print('truc' in tt)('truc', 3.14, 'truc')
Trueprint(colors)
print('truc' in colors)['red', 'blue', 3.14, 'black', 'white', ('truc', 3.14, 'truc')]
False('truc', 3.14, 'truc') in colorsTrueExplain this weird behaviour:
5 in [1, 2, 3, 4] == FalseFalse[1, 2, 3, 4] == FalseFalse5 not in [1, 2, 3, 4]True(5 in [1, 2, 3, 4]) == FalseTrue# ANSWER.
# This is a chained comparison. We have seen that
1 < 2 < 3
# is equivalent to
(1 < 2) and (2 < 3)
# so that
5 in [1, 2, 3, 4] == False
# is equivalent to
(5 in [1, 2, 3, 4]) and ([1, 2, 3, 4] == False)False(5 in [1, 2, 3, 4])False([1, 2, 3, 4] == False)Falsedict under the hood in Pythontel = {'emmanuelle': 5752, 'sebastian': 5578}
print(tel)
print(type(tel)){'emmanuelle': 5752, 'sebastian': 5578}
<class 'dict'>tel['emmanuelle'], tel['sebastian'](5752, 5578)tel['francis'] = '5919'
tel{'emmanuelle': 5752, 'sebastian': 5578, 'francis': '5919'}len(tel)3tel[7162453] = [1, 3, 2]
tel[3.14] = 'bidule'
tel[('jaouad', 2)] = 1234
tel{'emmanuelle': 5752,
'sebastian': 5578,
'francis': '5919',
7162453: [1, 3, 2],
3.14: 'bidule',
('jaouad', 2): 1234}sorted(tel)# A list is mutable
tel[['jaouad']] = '5678'tel[2]tel = {'emmanuelle': 5752, 'sebastian' : 5578, 'jaouad' : 1234}
print(tel.keys())
print(tel.values())
print(tel.items())dict_keys(['emmanuelle', 'sebastian', 'jaouad'])
dict_values([5752, 5578, 1234])
dict_items([('emmanuelle', 5752), ('sebastian', 5578), ('jaouad', 1234)])list(tel.keys())[2]'jaouad'tel.values().mappingmappingproxy({'emmanuelle': 5752, 'sebastian': 5578, 'jaouad': 1234})type(tel.keys())dict_keys'rémi' in telFalselist(tel)['emmanuelle', 'sebastian', 'jaouad']'rémi' in tel.keys()FalseYou can swap values like this
print(tel)
tel['emmanuelle'], tel['sebastian'] = tel['sebastian'], tel['emmanuelle']
print(tel){'emmanuelle': 5752, 'sebastian': 5578, 'jaouad': 1234}
{'emmanuelle': 5578, 'sebastian': 5752, 'jaouad': 1234}# It works, since
a, b = 2.71, 3.14
a, b = b, a
a, b(3.14, 2.71)Get keys of tel sorted by decreasing order
tel = {'emmanuelle': 5752, 'sebastian' : 5578, 'jaouad' : 1234}sorted(tel, reverse=True)['sebastian', 'jaouad', 'emmanuelle']type(sorted(tel, reverse=True))listGet keys of tel sorted by increasing values
tel = {'emmanuelle': 5752, 'sebastian' : 5578, 'jaouad' : 1234}tel["sebastian"]5578tel.get('rémi')sorted(tel, key=tel.get)['jaouad', 'sebastian', 'emmanuelle']Obtain a sorted-by-key version of tel
tel = {'emmanuelle': 5752, 'sebastian' : 5578, 'jaouad' : 1234}# Simplest is through a list
print(type(tel.items()))
issubclass(type(tel.items()), list)<class 'dict_items'>Falsesorted(tel.items())[('emmanuelle', 5752), ('jaouad', 1234), ('sebastian', 5578)]If you really want an ordered dict OrderDict memorizes order of insertion in it
from collections import OrderedDict
OrderedDict(sorted(tel.items()))OrderedDict([('emmanuelle', 5752), ('jaouad', 1234), ('sebastian', 5578)])A set is an unordered container, containing unique elements
ss = {1, 2, 2, 2, 3, 3, 'tintin', 'tintin', 'toto'}
ss{1, 2, 3, 'tintin', 'toto'}s = 'truc truc bidule truc'
set(s){' ', 'b', 'c', 'd', 'e', 'i', 'l', 'r', 't', 'u'}set(list(s)){' ', 'b', 'c', 'd', 'e', 'i', 'l', 'r', 't', 'u'}{1, 5, 2, 1, 1}.union({1, 2, 3}){1, 2, 3, 5}set( (1, 5, 3, 2)){1, 2, 3, 5}set([1, 5, 2, 1, 1]).intersection(set([1, 2, 3])){1, 2}ss.add('tintin')
ss{1, 2, 3, 'tintin', 'toto'}ss.difference(range(6)){'tintin', 'toto'}You can combine all containers together
dd = {
'truc': [1, 2, 3],
5: (1, 4, 2),
(1, 3): {'hello', 'world'}
}
dd{'truc': [1, 2, 3], 5: (1, 4, 2), (1, 3): {'hello', 'world'}}Python is name bindingss = {1, 2, 3}
sss = ss
sss, ss({1, 2, 3}, {1, 2, 3})id(ss), id(sss)(140143828586720, 140143828586720)sss.add("Truc")Question. What is in ss ?
ss, sss({1, 2, 3, 'Truc'}, {1, 2, 3, 'Truc'})ss and sss are names for the same object
id(ss), id(sss)(140143828586720, 140143828586720)ss is sssTruehelp('is')Comparisons
***********
Unlike C, all comparison operations in Python have the same priority,
which is lower than that of any arithmetic, shifting or bitwise
operation. Also unlike C, expressions like "a < b < c" have the
interpretation that is conventional in mathematics:
comparison ::= or_expr (comp_operator or_expr)*
comp_operator ::= "<" | ">" | "==" | ">=" | "<=" | "!="
| "is" ["not"] | ["not"] "in"
Comparisons yield boolean values: "True" or "False". Custom *rich
comparison methods* may return non-boolean values. In this case Python
will call "bool()" on such value in boolean contexts.
Comparisons can be chained arbitrarily, e.g., "x < y <= z" is
equivalent to "x < y and y <= z", except that "y" is evaluated only
once (but in both cases "z" is not evaluated at all when "x < y" is
found to be false).
Formally, if *a*, *b*, *c*, …, *y*, *z* are expressions and *op1*,
*op2*, …, *opN* are comparison operators, then "a op1 b op2 c ... y
opN z" is equivalent to "a op1 b and b op2 c and ... y opN z", except
that each expression is evaluated at most once.
Note that "a op1 b op2 c" doesn’t imply any kind of comparison between
*a* and *c*, so that, e.g., "x < y > z" is perfectly legal (though
perhaps not pretty).
Value comparisons
=================
The operators "<", ">", "==", ">=", "<=", and "!=" compare the values
of two objects. The objects do not need to have the same type.
Chapter Objects, values and types states that objects have a value (in
addition to type and identity). The value of an object is a rather
abstract notion in Python: For example, there is no canonical access
method for an object’s value. Also, there is no requirement that the
value of an object should be constructed in a particular way, e.g.
comprised of all its data attributes. Comparison operators implement a
particular notion of what the value of an object is. One can think of
them as defining the value of an object indirectly, by means of their
comparison implementation.
Because all types are (direct or indirect) subtypes of "object", they
inherit the default comparison behavior from "object". Types can
customize their comparison behavior by implementing *rich comparison
methods* like "__lt__()", described in Basic customization.
The default behavior for equality comparison ("==" and "!=") is based
on the identity of the objects. Hence, equality comparison of
instances with the same identity results in equality, and equality
comparison of instances with different identities results in
inequality. A motivation for this default behavior is the desire that
all objects should be reflexive (i.e. "x is y" implies "x == y").
A default order comparison ("<", ">", "<=", and ">=") is not provided;
an attempt raises "TypeError". A motivation for this default behavior
is the lack of a similar invariant as for equality.
The behavior of the default equality comparison, that instances with
different identities are always unequal, may be in contrast to what
types will need that have a sensible definition of object value and
value-based equality. Such types will need to customize their
comparison behavior, and in fact, a number of built-in types have done
that.
The following list describes the comparison behavior of the most
important built-in types.
* Numbers of built-in numeric types (Numeric Types — int, float,
complex) and of the standard library types "fractions.Fraction" and
"decimal.Decimal" can be compared within and across their types,
with the restriction that complex numbers do not support order
comparison. Within the limits of the types involved, they compare
mathematically (algorithmically) correct without loss of precision.
The not-a-number values "float('NaN')" and "decimal.Decimal('NaN')"
are special. Any ordered comparison of a number to a not-a-number
value is false. A counter-intuitive implication is that not-a-number
values are not equal to themselves. For example, if "x =
float('NaN')", "3 < x", "x < 3" and "x == x" are all false, while "x
!= x" is true. This behavior is compliant with IEEE 754.
* "None" and "NotImplemented" are singletons. **PEP 8** advises that
comparisons for singletons should always be done with "is" or "is
not", never the equality operators.
* Binary sequences (instances of "bytes" or "bytearray") can be
compared within and across their types. They compare
lexicographically using the numeric values of their elements.
* Strings (instances of "str") compare lexicographically using the
numerical Unicode code points (the result of the built-in function
"ord()") of their characters. [3]
Strings and binary sequences cannot be directly compared.
* Sequences (instances of "tuple", "list", or "range") can be compared
only within each of their types, with the restriction that ranges do
not support order comparison. Equality comparison across these
types results in inequality, and ordering comparison across these
types raises "TypeError".
Sequences compare lexicographically using comparison of
corresponding elements. The built-in containers typically assume
identical objects are equal to themselves. That lets them bypass
equality tests for identical objects to improve performance and to
maintain their internal invariants.
Lexicographical comparison between built-in collections works as
follows:
* For two collections to compare equal, they must be of the same
type, have the same length, and each pair of corresponding
elements must compare equal (for example, "[1,2] == (1,2)" is
false because the type is not the same).
* Collections that support order comparison are ordered the same as
their first unequal elements (for example, "[1,2,x] <= [1,2,y]"
has the same value as "x <= y"). If a corresponding element does
not exist, the shorter collection is ordered first (for example,
"[1,2] < [1,2,3]" is true).
* Mappings (instances of "dict") compare equal if and only if they
have equal "(key, value)" pairs. Equality comparison of the keys and
values enforces reflexivity.
Order comparisons ("<", ">", "<=", and ">=") raise "TypeError".
* Sets (instances of "set" or "frozenset") can be compared within and
across their types.
They define order comparison operators to mean subset and superset
tests. Those relations do not define total orderings (for example,
the two sets "{1,2}" and "{2,3}" are not equal, nor subsets of one
another, nor supersets of one another). Accordingly, sets are not
appropriate arguments for functions which depend on total ordering
(for example, "min()", "max()", and "sorted()" produce undefined
results given a list of sets as inputs).
Comparison of sets enforces reflexivity of its elements.
* Most other built-in types have no comparison methods implemented, so
they inherit the default comparison behavior.
User-defined classes that customize their comparison behavior should
follow some consistency rules, if possible:
* Equality comparison should be reflexive. In other words, identical
objects should compare equal:
"x is y" implies "x == y"
* Comparison should be symmetric. In other words, the following
expressions should have the same result:
"x == y" and "y == x"
"x != y" and "y != x"
"x < y" and "y > x"
"x <= y" and "y >= x"
* Comparison should be transitive. The following (non-exhaustive)
examples illustrate that:
"x > y and y > z" implies "x > z"
"x < y and y <= z" implies "x < z"
* Inverse comparison should result in the boolean negation. In other
words, the following expressions should have the same result:
"x == y" and "not x != y"
"x < y" and "not x >= y" (for total ordering)
"x > y" and "not x <= y" (for total ordering)
The last two expressions apply to totally ordered collections (e.g.
to sequences, but not to sets or mappings). See also the
"total_ordering()" decorator.
* The "hash()" result should be consistent with equality. Objects that
are equal should either have the same hash value, or be marked as
unhashable.
Python does not enforce these consistency rules. In fact, the
not-a-number values are an example for not following these rules.
Membership test operations
==========================
The operators "in" and "not in" test for membership. "x in s"
evaluates to "True" if *x* is a member of *s*, and "False" otherwise.
"x not in s" returns the negation of "x in s". All built-in sequences
and set types support this as well as dictionary, for which "in" tests
whether the dictionary has a given key. For container types such as
list, tuple, set, frozenset, dict, or collections.deque, the
expression "x in y" is equivalent to "any(x is e or x == e for e in
y)".
For the string and bytes types, "x in y" is "True" if and only if *x*
is a substring of *y*. An equivalent test is "y.find(x) != -1".
Empty strings are always considered to be a substring of any other
string, so """ in "abc"" will return "True".
For user-defined classes which define the "__contains__()" method, "x
in y" returns "True" if "y.__contains__(x)" returns a true value, and
"False" otherwise.
For user-defined classes which do not define "__contains__()" but do
define "__iter__()", "x in y" is "True" if some value "z", for which
the expression "x is z or x == z" is true, is produced while iterating
over "y". If an exception is raised during the iteration, it is as if
"in" raised that exception.
Lastly, the old-style iteration protocol is tried: if a class defines
"__getitem__()", "x in y" is "True" if and only if there is a non-
negative integer index *i* such that "x is y[i] or x == y[i]", and no
lower integer index raises the "IndexError" exception. (If any other
exception is raised, it is as if "in" raised that exception).
The operator "not in" is defined to have the inverse truth value of
"in".
Identity comparisons
====================
The operators "is" and "is not" test for an object’s identity: "x is
y" is true if and only if *x* and *y* are the same object. An
Object’s identity is determined using the "id()" function. "x is not
y" yields the inverse truth value. [4]
Related help topics: EXPRESSIONS, BASICMETHODS
When you code
x = [1, 2, 3]
y = xyou just - bind the variable name x to a list [1, 2, 3] - give another name y to the same object
Important remarks
id(1), id(1+1), id(2)(140143894380784, 140143894380816, 140143894380816)A list is mutable
x = [1, 2, 3]
print(id(x), x)
x[0] += 42; x.append(3.14)
print(id(x), x)140143828322240 [1, 2, 3]
140143828322240 [43, 2, 3, 3.14]A str is immutable
In order to “change” an immutable object, Python creates a new one
s = 'to'
print(id(s), s)
s += 'to'
print(id(s), s)140143889616432 to
140143828402480 totoOnce again, a list is mutable
super_list = [3.14, (1, 2, 3), 'tintin']
other_list = super_list
id(other_list), id(super_list)(140143828457216, 140143828457216)other_list and super_list are the same listid returns the identity of an object. Two objects with the same idendity are the same (not only the same type, but the same instance)other_list[1] = 'youps'
other_list, super_list([3.14, 'youps', 'tintin'], [3.14, 'youps', 'tintin'])id(super_list), id(other_list)(140143828457216, 140143828457216)other_list = super_list.copy()
id(other_list), id(super_list)(140142248317824, 140143828457216)other_list[1] = 'copy'
other_list, super_list([3.14, 'copy', 'tintin'], [3.14, 'youps', 'tintin'])Only other_list is modified.
But… what if you have a list of list ? (or a mutable object containing mutable objects)
l1, l2 = [1, 2, 3], [4, 5, 6]
list_list = [l1, l2]
list_list[[1, 2, 3], [4, 5, 6]]id(list_list), id(list_list[0]), id(l1), list_list[0] is l1(140142153134336, 140142153387200, 140142153387200, True)Let’s make a copy of list_list
copy_list = list_list.copy()
copy_list.append('super')
list_list, copy_list([[1, 2, 3], [4, 5, 6]], [[1, 2, 3], [4, 5, 6], 'super'])id(list_list[0]), id(copy_list[0])(140142153387200, 140142153387200)OK, only copy_list is modified, as expected
But now…
copy_list[0][1] = 'oups'
copy_list, list_list([[1, 'oups', 3], [4, 5, 6], 'super'], [[1, 'oups', 3], [4, 5, 6]])Question. What happened ?!?
list_list object is copiedcopy does a shallow copy, not a deep copydeepcopy.from copy import deepcopy
copy_list = deepcopy(list_list)
copy_list[0][1] = 'incredible !'
list_list, copy_list([[1, 'oups', 3], [4, 5, 6]], [[1, 'incredible !', 3], [4, 5, 6]])tt = ([1, 2, 3], [4, 5, 6])
print(id(tt), tt)
print(list(map(id, tt)))140142153248448 ([1, 2, 3], [4, 5, 6])
[140143828522688, 140143828456448]tt[0][1] = '42'
print(id(tt), tt)
print(list(map(id, tt)))140142153248448 ([1, '42', 3], [4, 5, 6])
[140143828522688, 140143828456448]s = [1, 2, 3]s2 = ss2 is sTrueid(s2), id(s)(140142153136192, 140142153136192)Namely tests, loops, again booleans, etc.
if 2 ** 2 == 5:
print('Obvious')
else:
print('YES')
print('toujours')YES
toujoursa = 3
if a > 0:
if a == 1:
print(1)
elif a == 2:
print(2)
elif a == 2:
print(2)
elif a == 3:
print(3)
else:
print(a)For example, don’t do this to test if a list is empty
l2 = ['hello', 'everybody']
if len(l2) > 0:
print(l2[0])hellobut this
if l2:
print(l2[0])helloSome poetry
dict is Falsestring is Falselist is Falsetuple is Falseset is False0 is False.0 is FalseTrueEmpty sequences are falsies
Non-empty sequences are truthies
a = 10
b = 1
while b < a:
b = b + 1
print(b)2
3
4
5
6
7
8
9
10Compute the decimals of Pi using the Wallis formula
\[ \pi = 2 \prod_{i=1}^{100} \frac{4i^2}{4i^2 - 1} \]
pi = 2
eps = 1e-10
dif = 2 * eps
i = 1
while dif > eps:
pi, i, old_pi = pi * 4 * i ** 2 / (4 * i ** 2 - 1), i + 1, pi
dif = pi - old_pipi3.1415837914138556import math
math.pi3.141592653589793for loop with rangerange has the same parameters as with slicing start:end:stride, all parameters being optionalfor i in range(10):
print(i)0
1
2
3
4
5
6
7
8
9for i in range(4):
print(i + 1)
print('-')
for i in range(1, 5):
print(i)
print('-')
for i in range(1, 10, 3):
print(i)1
2
3
4
-
1
2
3
4
-
1
4
7Something for nerds. You can use else in a for loop
names = ['stephane', 'mokhtar', 'jaouad', 'simon', 'yiyang']
for name in names:
if name.startswith('u'):
print(name)
break
else:
print('Not found.')Not found.names = ['stephane', 'mokhtar', 'jaouad', 'ulysse', 'simon', 'yiyang']
for name in names:
if name.startswith('u'):
print(name)
break
else:
print('Not found.')ulysseYou can iterate using for over any container: list, tuple, dict, str, set among others…
colors = ['red', 'blue', 'black', 'white']
peoples = ['stephane', 'jaouad', 'mokhtar', 'yiyang', 'rémi']# This is stupid
for i in range(len(colors)):
print(colors[i])
# This is better
for color in colors:
print(color)red
blue
black
white
red
blue
black
whiteTo iterate over several sequences at the same time, use zip
for color, people in zip(colors, peoples):
print(color, people)red stephane
blue jaouad
black mokhtar
white yiyangl = ["Bonjour", {'francis': 5214, 'stephane': 5123}, ('truc', 3)]
for e in l:
print(e, len(e))Bonjour 7
{'francis': 5214, 'stephane': 5123} 2
('truc', 3) 2Loop over a str
s = 'Bonjour'
for c in s:
print(c)B
o
n
j
o
u
rLoop over a dict
dd = {(1, 3): {'hello', 'world'}, 'truc': [1, 2, 3], 5: (1, 4, 2)}
# Default is to loop over keys
for key in dd:
print(key)(1, 3)
truc
5# Loop over values
for e in dd.values():
print(e){'hello', 'world'}
[1, 2, 3]
(1, 4, 2)# Loop over items (key, value) pairs
for key, val in dd.items():
print(key, val)(1, 3) {'hello', 'world'}
truc [1, 2, 3]
5 (1, 4, 2)for t in dd.items():
print(t)((1, 3), {'hello', 'world'})
('truc', [1, 2, 3])
(5, (1, 4, 2))You can construct a list, dict, set and others using the comprehension syntax
list comprehension
print(colors)
print(peoples)['red', 'blue', 'black', 'white']
['stephane', 'jaouad', 'mokhtar', 'yiyang', 'rémi']l = []
for p, c in zip(peoples, colors):
if len(c)<=4 :
l.append(p)
print(l)['stephane', 'jaouad']# The list of people with favorite color that has no more than 4 characters
[people for color, people in zip(colors, peoples) if len(color) <= 4]['stephane', 'jaouad']dict comprehension
{people: color for color, people in zip(colors, peoples) if len(color) <= 4}{'stephane': 'red', 'jaouad': 'blue'}# Allows to build a dict from two lists (for keys and values)
{key: value for (key, value) in zip(peoples, colors)}{'stephane': 'red', 'jaouad': 'blue', 'mokhtar': 'black', 'yiyang': 'white'}# But it's simpler (so better) to use
dict(zip(peoples, colors)){'stephane': 'red', 'jaouad': 'blue', 'mokhtar': 'black', 'yiyang': 'white'}Something very convenient is enumerate
for i, color in enumerate(colors):
print(i, color)0 red
1 blue
2 black
3 whitelist(enumerate(colors))[(0, 'red'), (1, 'blue'), (2, 'black'), (3, 'white')]dict(enumerate(s)){0: 'B', 1: 'o', 2: 'n', 3: 'j', 4: 'o', 5: 'u', 6: 'r'}print(dict(enumerate(s))){0: 'B', 1: 'o', 2: 'n', 3: 'j', 4: 'o', 5: 'u', 6: 'r'}s = 'Hey everyone'
{c: i for i, c in enumerate(s)}{'H': 0, 'e': 11, 'y': 8, ' ': 3, 'v': 5, 'r': 7, 'o': 9, 'n': 10}We can use lambda to define anonymous functions, and use them in the map and reduce functions
square = lambda x: x ** 2
square(2)4type(square)functiondir(square)['__annotations__',
'__builtins__',
'__call__',
'__class__',
'__closure__',
'__code__',
'__defaults__',
'__delattr__',
'__dict__',
'__dir__',
'__doc__',
'__eq__',
'__format__',
'__ge__',
'__get__',
'__getattribute__',
'__globals__',
'__gt__',
'__hash__',
'__init__',
'__init_subclass__',
'__kwdefaults__',
'__le__',
'__lt__',
'__module__',
'__name__',
'__ne__',
'__new__',
'__qualname__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__setattr__',
'__sizeof__',
'__str__',
'__subclasshook__']s = "a"square("a")sum2 = lambda a, b: a + b
print(sum2('Hello', ' world'))
print(sum2(1, 2))Hello world
3Intended for short and one-line function.
More complex functions use def (see below)
Print the squares of even numbers between 0 et 15
maplist()
[i**2 for i in range(0,15,2)][0, 4, 16, 36, 64, 100, 144, 196][][]# Answer to 1.
[i ** 2 for i in range(15) if i % 2 == 0][0, 4, 16, 36, 64, 100, 144, 196]# Answer to 2.
list(map(lambda x: x ** 2, range(0, 15, 2)))[0, 4, 16, 36, 64, 100, 144, 196]Remark. We will see later why we need to use list above
map(lambda x: x ** 2, range(0, 15, 2))<map at 0x7f75c721b4f0>Now, to get the sum of these squares, we can use sum
sum(map(lambda x: x ** 2, range(0, 15, 2)))560We can also use reduce (not a good idea here, but it’s good to know that it exists)
from functools import reduce
reduce(lambda a, b: a + b, map(lambda x: x ** 2, range(0, 15, 2)))560There is also something that can be useful in functool called partial
It allows to simplify functions by freezing some arguments
from functools import partial
def mult(a, b):
return a * b
double = partial(mult, b=2)
double(2) 4What is the output of
reduce(lambda a, b: a + b[0] * b[1], enumerate('abcde'), 'A')reduce(lambda a, b: a + b[0] * b[1],
enumerate('abcde'), 'A')'Abccdddeeee'This does the following
list(enumerate('abcde'))[(0, 'a'), (1, 'b'), (2, 'c'), (3, 'd'), (4, 'e')]((((('A' + 0 * 'a') + 1 * 'b') + 2 * 'c') + 3 * 'd') + 4 * 'e')'Abccdddeeee'import sys
import matplotlib.pyplot as plt
%matplotlib inlineplt.figure(figsize=(6, 6))
plt.plot([sys.getsizeof(list(range(i))) for i in range(10000)], lw=3)
plt.plot([sys.getsizeof(range(i)) for i in range(10000)], lw=3)
plt.xlabel('Number of elements (value of i)', fontsize=14)
plt.ylabel('Size (in bytes)', fontsize=14)
_ = plt.legend(['list(range(i))', 'range(i)'], fontsize=16)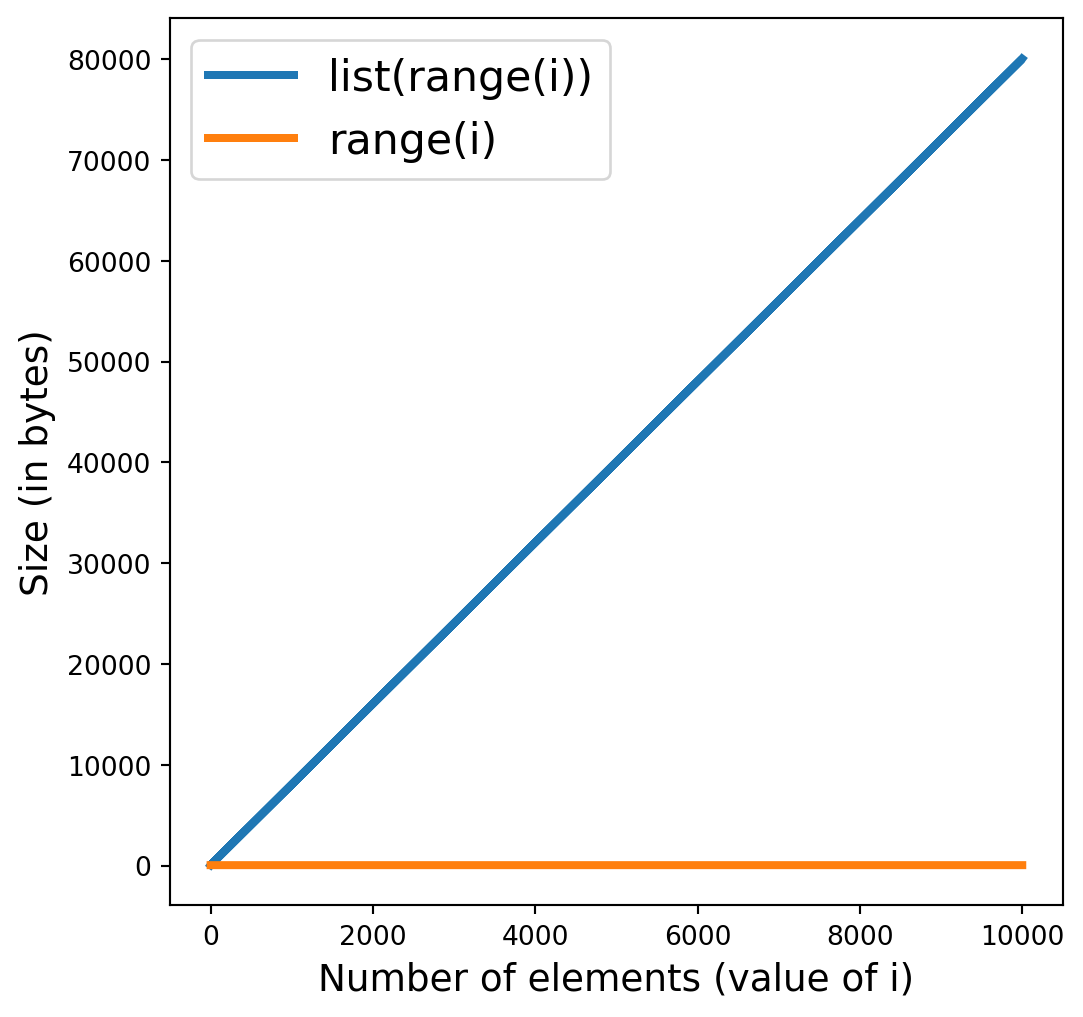
The memory used by range(i) does not scale linearly with i
What is happening ?
range(n) does not allocate a list of n elements !PythonPython standard library behaves like thisWarning. Getting the real memory footprint of a Python object is difficult. Note that sizeof calls the __sizeof__ method of r, which does not give in general the actual memory used by an object. But nevermind here.
The following computation has no memory footprint:
sum(range(10**8))4999999950000000map(lambda x: x**2, range(10**7))<map at 0x7f7561b402b0>map does not return a list for the same reason
sum(map(lambda x: x**2, range(10**6)))333332833333500000Namely generators defined through comprehensions. Just replace [] by () in the comprehension.
A generator can be iterated on only once
range(10)range(0, 10)carres = (i**2 for i in range(10))carres<generator object <genexpr> at 0x7f7561b82340>for c in carres:
print(c)0
1
4
9
16
25
36
49
64
81for i in range(4):
for j in range(3):
print(i, j)0 0
0 1
0 2
1 0
1 1
1 2
2 0
2 1
2 2
3 0
3 1
3 2from itertools import product
for t in product(range(4), range(3)):
print(t)(0, 0)
(0, 1)
(0, 2)
(1, 0)
(1, 1)
(1, 2)
(2, 0)
(2, 1)
(2, 2)
(3, 0)
(3, 1)
(3, 2)from itertools import product
gene = (i + j for i, j in product(range(3), range(3)))
gene<generator object <genexpr> at 0x7f7561b827a0>print(list(gene))
print(list(gene))[0, 1, 2, 1, 2, 3, 2, 3, 4]
[]yieldSomething very powerful
def startswith(words, letter):
for word in words:
if word.startswith(letter):
yield wordwords = [
'Python', "is", 'awesome', 'in', 'particular', 'generators',
'are', 'really', 'cool'
]list(word for word in words if word.startswith("a"))['awesome', 'are']list(startswith(words, letter='a'))['awesome', 'are']a = 2float(a)2.0But also with a for loop
for word in startswith(words, letter='a'):
print(word)awesome
areit = startswith(words, letter='a')type(it)generatornext(it)'awesome'next(it)'are'next(it)collections module(This is where the good stuff hides)
texte = """
Bonjour,
Python c'est super.
Python ca a l'air quand même un peu compliqué.
Mais bon, ca a l'air pratique.
Peut-être que je pourrais m'en servir pour faire des trucs super.
"""
texte" \nBonjour,\nPython c'est super.\nPython ca a l'air quand même un peu compliqué.\nMais bon, ca a l'air pratique.\nPeut-être que je pourrais m'en servir pour faire des trucs super.\n"print(texte)
Bonjour,
Python c'est super.
Python ca a l'air quand même un peu compliqué.
Mais bon, ca a l'air pratique.
Peut-être que je pourrais m'en servir pour faire des trucs super.
# Some basic text preprocessing
new_text = (
texte
.strip()
.replace('\n', ' ')
.replace(',', ' ')
.replace('.', ' ')
.replace("'", ' ')
)
print(new_text)
print('-' * 8)
words = new_text.split()
print(words)Bonjour Python c est super Python ca a l air quand même un peu compliqué Mais bon ca a l air pratique Peut-être que je pourrais m en servir pour faire des trucs super
--------
['Bonjour', 'Python', 'c', 'est', 'super', 'Python', 'ca', 'a', 'l', 'air', 'quand', 'même', 'un', 'peu', 'compliqué', 'Mais', 'bon', 'ca', 'a', 'l', 'air', 'pratique', 'Peut-être', 'que', 'je', 'pourrais', 'm', 'en', 'servir', 'pour', 'faire', 'des', 'trucs', 'super']Count the number of occurences of all the words in words.
Output must be a dictionary containg word: count
print(words)['Bonjour', 'Python', 'c', 'est', 'super', 'Python', 'ca', 'a', 'l', 'air', 'quand', 'même', 'un', 'peu', 'compliqué', 'Mais', 'bon', 'ca', 'a', 'l', 'air', 'pratique', 'Peut-être', 'que', 'je', 'pourrais', 'm', 'en', 'servir', 'pour', 'faire', 'des', 'trucs', 'super']words_counts = {}
for word in words:
if word in words_counts:
words_counts[word] += 1
else:
words_counts[word] = 1
print(words_counts){'Bonjour': 1, 'Python': 2, 'c': 1, 'est': 1, 'super': 2, 'ca': 2, 'a': 2, 'l': 2, 'air': 2, 'quand': 1, 'même': 1, 'un': 1, 'peu': 1, 'compliqué': 1, 'Mais': 1, 'bon': 1, 'pratique': 1, 'Peut-être': 1, 'que': 1, 'je': 1, 'pourrais': 1, 'm': 1, 'en': 1, 'servir': 1, 'pour': 1, 'faire': 1, 'des': 1, 'trucs': 1}defaultdictint()0from collections import defaultdict
words_counts = defaultdict(int)
for word in words:
words_counts[word] += 1
print(words_counts)defaultdict(<class 'int'>, {'Bonjour': 1, 'Python': 2, 'c': 1, 'est': 1, 'super': 2, 'ca': 2, 'a': 2, 'l': 2, 'air': 2, 'quand': 1, 'même': 1, 'un': 1, 'peu': 1, 'compliqué': 1, 'Mais': 1, 'bon': 1, 'pratique': 1, 'Peut-être': 1, 'que': 1, 'je': 1, 'pourrais': 1, 'm': 1, 'en': 1, 'servir': 1, 'pour': 1, 'faire': 1, 'des': 1, 'trucs': 1})defaultdict can be extremely usefulint is created (defaults to 0) if key is not founddefaultdictdefaultdictaddresses = defaultdict(lambda: 'unknown')
addresses['huyen']
addresses['stephane'] = '8 place Aurelie Nemours'
print(addresses)defaultdict(<function <lambda> at 0x7f7561bb6320>, {'huyen': 'unknown', 'stephane': '8 place Aurelie Nemours'})# Somewhat nasty...
print('jean-francois' in addresses)
print(addresses['jean-francois'])
print('jean-francois' in addresses)False
unknown
Truecounterfrom collections import Counter
print(dict(Counter(words))){'Bonjour': 1, 'Python': 2, 'c': 1, 'est': 1, 'super': 2, 'ca': 2, 'a': 2, 'l': 2, 'air': 2, 'quand': 1, 'même': 1, 'un': 1, 'peu': 1, 'compliqué': 1, 'Mais': 1, 'bon': 1, 'pratique': 1, 'Peut-être': 1, 'que': 1, 'je': 1, 'pourrais': 1, 'm': 1, 'en': 1, 'servir': 1, 'pour': 1, 'faire': 1, 'des': 1, 'trucs': 1}Counter counts the number of occurences of all objects in an iterable
Question. Which one do you prefer ?
Counter one right ?When you need to do something, assume that there is a tool to do it directly
If you can’t find it, ask google or stackoverflow
Otherwise, try to do it as simply as possible
Compute the number of occurences AND the length of each word in words.
Output must be a dictionary containing word: (count, length)
from collections import Counter
{word: (count, len(word)) for word, count in Counter(words).items()}{'Bonjour': (1, 7),
'Python': (2, 6),
'c': (1, 1),
'est': (1, 3),
'super': (2, 5),
'ca': (2, 2),
'a': (2, 1),
'l': (2, 1),
'air': (2, 3),
'quand': (1, 5),
'même': (1, 4),
'un': (1, 2),
'peu': (1, 3),
'compliqué': (1, 9),
'Mais': (1, 4),
'bon': (1, 3),
'pratique': (1, 8),
'Peut-être': (1, 9),
'que': (1, 3),
'je': (1, 2),
'pourrais': (1, 8),
'm': (1, 1),
'en': (1, 2),
'servir': (1, 6),
'pour': (1, 4),
'faire': (1, 5),
'des': (1, 3),
'trucs': (1, 5)}namedtupleThere is also the namedtuple. It’s a tuple but with named attributes
from collections import namedtuple
Jedi = namedtuple('Jedi', ['firstname', 'lastname', 'age', 'color'])
yoda = Jedi('Minch', 'Yoda', 900, 'green')
yodaJedi(firstname='Minch', lastname='Yoda', age=900, color='green')yoda.firstname'Minch'yoda[1]'Yoda'Remark. A better alternative since Python 3.7 is dataclasses. We will talk about it later
Next, put a text file miserables.txt in the folder containing this notebook. If it is not there, the next cell downloads it, if is it there, then we do nothing.
import requests
import os
# The path containing your notebook
path_data = './'
# The name of the file
filename = 'miserables.txt'
if os.path.exists(os.path.join(path_data, filename)):
print('The file %s already exists.' % os.path.join(path_data, filename))
else:
url = 'https://stephanegaiffas.github.io/big_data_course/data/miserables.txt'
r = requests.get(url)
with open(os.path.join(path_data, filename), 'wb') as f:
f.write(r.content)
print('Downloaded file %s.' % os.path.join(path_data, filename))Downloaded file ./miserables.txt.ls -alhtotal 3,5M
drwxrwxr-x 4 boucheron boucheron 4,0K janv. 30 13:38 ./
drwxrwxr-x 8 boucheron boucheron 4,0K janv. 30 13:33 ../
-rw-rw-r-- 1 boucheron boucheron 163 janv. 30 13:33 fruits.csv
drwxrwxr-x 2 boucheron boucheron 4,0K janv. 29 21:33 img/
drwxrwxr-x 2 boucheron boucheron 4,0K janv. 29 23:35 .ipynb_checkpoints/
-rw-rw-r-- 1 boucheron boucheron 3,1M janv. 30 13:38 miserables.txt
-rw-rw-r-- 1 boucheron boucheron 44 janv. 30 11:51 miserable_word_counts.pkl
-rw-rw-r-- 1 boucheron boucheron 162K janv. 30 13:38 notebook01_python.ipynb
-rw-rw-r-- 1 boucheron boucheron 70K janv. 29 20:23 notebook01_python.qmd
-rw-rw-r-- 1 boucheron boucheron 61K janv. 30 08:29 notebook02_numpy.ipynb
-rw-rw-r-- 1 boucheron boucheron 28K janv. 29 17:24 notebook02_numpy.qmd
-rw-rw-r-- 1 boucheron boucheron 32K janv. 30 13:32 notebook03_pandas.qmd
-rw-rw-r-- 1 boucheron boucheron 24K janv. 26 23:12 notebook04_pandas.qmd
-rw-rw-r-- 1 boucheron boucheron 7,8K janv. 29 22:13 tips.csv!rm -f miserables.txtos.path.join(path_data, filename)'./miserables.txt'In jupyter and ipython you can run terminal command lines using !
Let’s count number of lines and number of words with the wc command-line tool (linux or mac only, don’t ask me how on windows)
# Lines count
!wc -l miserables.txtwc: miserables.txt: No such file or directory# Word count
!wc -w miserables.txtwc: miserables.txt: No such file or directoryCount the number of occurences of each word in the text file miserables.txt. We use a open context and the Counter from before.
from collections import Counter
counter = Counter()
with open('miserables.txt', encoding='utf8') as f:
for line_idx, line in enumerate(f):
line = line.strip().replace('\n', ' ')\
.replace(',', ' ')\
.replace('.', ' ')\
.replace('»', ' ')\
.replace('-', ' ')\
.replace('!', ' ')\
.replace('(', ' ')\
.replace(')', ' ')\
.replace('?', ' ').split()
counter.update(line)FileNotFoundError: [Errno 2] No such file or directory: 'miserables.txt'counterCounter()counter.most_common(500)[]A context in Python is something that we use with the with keyword.
It allows to deal automatically with the opening and the closing of the file.
Note the for loop:
for line in f:
...You loop directly over the lines of the open file from within the open context
pickleYou can save your computation with pickle.
pickle is a way of saving almost anything with Python.import pickle as pkl
# Let's save it
with open('miserable_word_counts.pkl', 'wb') as f:
pkl.dump(counter, f)
# And read it again
with open('miserable_word_counts.pkl', 'rb') as f:
counter = pkl.load(f)counter.most_common(10)[]You must use function to order and reuse code
Function blocks must be indented as other control-flow blocks.
def test():
return 'in test function'
test()'in test function'Functions can optionally return values. By default, functions return None.
The syntax to define a function:
def keyword;return object for optionally returning values.None is NoneTruedef f(x):
return x + 10
f(20)30A function that returns several elements returns a tuple
def f(x):
return x + 1, x + 4
f(5)(6, 9)type(f)functionf.truc = "bonjour"type(f(5))tupleMandatory parameters (positional arguments)
def double_it(x):
return x * 2
double_it(2)4double_it()TypeError: double_it() missing 1 required positional argument: 'x'Optimal parameters
def double_it(x=2):
return x * 2
double_it()4double_it(3)6def f(x, y=2, z=10):
print(x, '+', y, '+', z, '=', x + y + z)f(5)5 + 2 + 10 = 17f(5, -2)5 + -2 + 10 = 13f(5, -2, 8)5 + -2 + 8 = 11f(z=5, x=-2, y=8)-2 + 8 + 5 = 11You can do stuff like this, using unpacking * notation
a, *b, c = 1, 2, 3, 4, 5
a, b, c(1, [2, 3, 4], 5)Back to function f you can unpack a tuple as positional arguments
tt = (1, 2, 3)
f(*tt)1 + 2 + 3 = 6dd = {'y': 10, 'z': -5}f(3, **dd)3 + 10 + -5 = 8def g(x, z, y, t=1, u=2):
print(x, '+', y, '+', z, '+', t, '+',
u, '=', x + y + z + t + u)tt = (1, -4, 2)
dd = {'t': 10, 'u': -5}
g(*tt, **dd)1 + 2 + -4 + 10 + -5 = 4Pythondef f(*args, **kwargs):
print('args=', args)
print('kwargs=', kwargs)
f(1, 2, 'truc', lastname='gaiffas', firstname='stephane')args= (1, 2, 'truc')
kwargs= {'lastname': 'gaiffas', 'firstname': 'stephane'}* for argument unpacking and ** for keyword argument unpackingargs and kwargs are a convention, not mandatory# How to get fired
def f(*aaa, **bbb):
print('args=', aaa)
print('kwargs=', bbb)
f(1, 2, 'truc', lastname='gaiffas', firstname='stephane') args= (1, 2, 'truc')
kwargs= {'lastname': 'gaiffas', 'firstname': 'stephane'}Remark. A function is a regular an object… you can add attributes on it !
f.truc = 4f(1, 3)args= (1, 3)
kwargs= {}f(3, -2, y='truc')args= (3, -2)
kwargs= {'y': 'truc'}Python supports object-oriented programming (OOP). The goals of OOP are:
Here is a small example: we create a Student class, which is an object gathering several custom functions (called methods) and variables (called attributes).
class Student(object):
def __init__(self, name, birthyear, major='computer science'):
self.name = name
self.birthyear = birthyear
self.major = major
def __repr__(self):
return "Student(name='{name}', birthyear={birthyear}, major='{major}')"\
.format(name=self.name, birthyear=self.birthyear, major=self.major)
anna = Student('anna', 1987)
annaStudent(name='anna', birthyear=1987, major='computer science')The __repr__ is what we call a ‘magic method’ in Python, that allows to display an object as a string easily. There is a very large number of such magic methods. There are used to implement interfaces
Add a age method to the Student class that computes the age of the student. - You can (and should) use the datetime module. - Since we only know about the birth year, let’s assume that the day of the birth is January, 1st.
from datetime import datetime
class Student(object):
def __init__(self, name, birthyear, major='computer science'):
self.name = name
self.birthyear = birthyear
self.major = major
def __repr__(self):
return "Student(name='{name}', birthyear={birthyear}, major='{major}')"\
.format(name=self.name, birthyear=self.birthyear, major=self.major)
def age(self):
return datetime.now().year - self.birthyear
anna = Student('anna', 1987)
anna.age()37We can make methods look like attributes using properties, as shown below
class Student(object):
def __init__(self, name, birthyear, major='computer science'):
self.name = name
self.birthyear = birthyear
self.major = major
def __repr__(self):
return "Student(name='{name}', birthyear={birthyear}, major='{major}')"\
.format(name=self.name, birthyear=self.birthyear, major=self.major)
@property
def age(self):
return datetime.now().year - self.birthyear
anna = Student('anna', 1987)
anna.age37A MasterStudent is a Student with a new extra mandatory internship attribute
"%d" % 2'2'x = 2
f"truc {x}"'truc 2'class MasterStudent(Student):
def __init__(self, name, age, internship, major='computer science'):
# Student.__init__(self, name, age, major)
Student.__init__(self, name, age, major)
self.internship = internship
def __repr__(self):
return f"MasterStudent(name='{self.name}', internship={self.internship}, birthyear={self.birthyear}, major={self.major})"
MasterStudent('djalil', 22, 'pwc')MasterStudent(name='djalil', internship=pwc, birthyear=22, major=computer science)class MasterStudent(Student):
def __init__(self, name, age, internship, major='computer science'):
# Student.__init__(self, name, age, major)
Student.__init__(self, name, age, major)
self.internship = internship
def __repr__(self):
return "MasterStudent(name='{name}', internship='{internship}'" \
", birthyear={birthyear}, major='{major}')"\
.format(name=self.name, internship=self.internship,
birthyear=self.birthyear, major=self.major)
djalil = MasterStudent('djalil', 1996, 'pwc')djalil.__dict__{'name': 'djalil',
'birthyear': 1996,
'major': 'computer science',
'internship': 'pwc'}djalil.birthyear1996djalil.__dict__["birthyear"]1996Python are objects and actually dicts under the hood…class Monkey(object):
def __init__(self, name):
self.name = name
def describe(self):
print("Old monkey %s" % self.name)
def patch(self):
print("New monkey %s" % self.name)
monkey = Monkey("Baloo")
monkey.describe()
Monkey.describe = patch
monkey.describe()Old monkey Baloo
New monkey Baloomonkeys = [Monkey("Baloo"), Monkey("Super singe")]
monkey_name = monkey.name
for i in range(1000):
monkey_nameSince Python 3.7 you can use a dataclass for this
Does a lot of work for you (produces the __repr__ among many other things for you)
from dataclasses import dataclass
from datetime import datetime
@dataclass
class Student(object):
name: str
birthyear: int
major: str = 'computer science'
@property
def age(self):
return datetime.now().year - self.birthyear
anna = Student(name="anna", birthyear=1987)
annaStudent(name='anna', birthyear=1987, major='computer science')print(anna.age)37PythonFirst, best way to learn and practice:
Start with the official tutorial https://docs.python.org/fr/3/tutorial/index.html
Look at https://python-3-for-scientists.readthedocs.io/en/latest/index.html
Continue with the documentation at https://docs.python.org/fr/3/index.html and work!
def foo(bar=[]):
bar.append('oops')
return bar
print(foo())
print(foo())
print(foo())
print('-' * 8)
print(foo(['Ah ah']))
print(foo([]))['oops']
['oops', 'oops']
['oops', 'oops', 'oops']
--------
['Ah ah', 'oops']
['oops']print(foo.__defaults__)
foo()
print(foo.__defaults__)(['oops', 'oops', 'oops'],)
(['oops', 'oops', 'oops', 'oops'],)the bar argument is initialized to its default (i.e., an empty list) only when foo() is first definedfoo() (with no a bar argument specified) use the same list!One should use instead
def foo(bar=None):
if bar is None:
bar = []
bar.append('oops')
return bar
print(foo())
print(foo())
print(foo())
print(foo(['OK']))['oops']
['oops']
['oops']
['OK', 'oops']print(foo.__defaults__)
foo()
print(foo.__defaults__)(None,)
(None,)No problem with immutable types
def foo(bar=()):
bar += ('oops',)
return bar
print(foo())
print(foo())
print(foo())('oops',)
('oops',)
('oops',)print(foo.__defaults__)((),)class A(object):
x = 1
def __init__(self):
self.y = 2
class B(A):
def __init__(self):
super().__init__()
class C(A):
def __init__(self):
super().__init__()
a, b, c = A(), B(), C()print(a.x, b.x, c.x)
print(a.y, b.y, c.y)1 1 1
2 2 2a.y = 3
print(a.y, b.y, c.y)3 2 2a.x = 3 # Adds a new attribute named x in object a
print(a.x, b.x, c.x)3 1 1A.x = 4 # Changes the class attribute x of class A
print(a.x, b.x, c.x)3 4 4x is not an attribute of b nor cB and CA, which contains a class attribute xClasses and objects contain a hidden dict to store their attributes, and are accessed following a method resolution order (MRO)
a.__dict__, b.__dict__, c.__dict__({'y': 3, 'x': 3}, {'y': 2}, {'y': 2})A.__dict__, B.__dict__, C.__dict__(mappingproxy({'__module__': '__main__',
'x': 4,
'__init__': <function __main__.A.__init__(self)>,
'__dict__': <attribute '__dict__' of 'A' objects>,
'__weakref__': <attribute '__weakref__' of 'A' objects>,
'__doc__': None}),
mappingproxy({'__module__': '__main__',
'__init__': <function __main__.B.__init__(self)>,
'__doc__': None}),
mappingproxy({'__module__': '__main__',
'__init__': <function __main__.C.__init__(self)>,
'__doc__': None}))This can lead to nasty errors when using class attributes: learn more about this
ints += [4]NameError: name 'ints' is not definedintsNameError: name 'ints' is not definedints = [1]
def foo1():
ints.append(2)
return ints
def foo2():
ints += [2]
return intsfoo1()[1, 2]foo2()UnboundLocalError: local variable 'ints' referenced before assignmentints += [2]means
ints = ints + [2]which is an assigment: ints must be defined in the local scope, but it is not, while
ints.append(2)is not an assignemnt
list while iterating over itodd = lambda x: bool(x % 2)
numbers = list(range(10))
for i in range(len(numbers)):
if odd(numbers[i]):
del numbers[i]IndexError: list index out of rangeTypically an example where one should use a list comprehension
[number for number in numbers if not odd(number)][0, 2, 4, 6, 8]Accept to spend time to write clean docstrings (my favourite is the numpydoc style)
def create_student(name, age, address, major='computer science'):
"""Add a student in the database
Parameters
----------
name: `str`
Name of the student
age: `int`
Age of the student
address: `str`
Address of the student
major: `str`, default='computer science'
The major chosen by the student
Returns
-------
output: `Student`
A fresh student
"""
passcreate_student()TypeError: create_student() missing 3 required positional arguments: 'name', 'age', and 'address'dd = {'stephane': 1234, 'gael': 4567, 'gontran': 891011}
# Bad
for key in dd.keys():
print(key, dd[key])
print('-' * 8)
# Good
for key, value in dd.items():
print(key, value)stephane 1234
gael 4567
gontran 891011
--------
stephane 1234
gael 4567
gontran 891011colors = ['black', 'yellow', 'brown', 'red', 'pink']
# Bad
for i in range(len(colors)):
print(i, colors[i])
print('-' * 8)
# Good
for i, color in enumerate(colors):
print(i, color)0 black
1 yellow
2 brown
3 red
4 pink
--------
0 black
1 yellow
2 brown
3 red
4 pinkWhile it’s always better than a hand-made solution
list1 = [1, 2]
list2 = [3, 4]
list3 = [5, 6, 7]
for a in list1:
for b in list2:
for c in list3:
print(a, b, c)1 3 5
1 3 6
1 3 7
1 4 5
1 4 6
1 4 7
2 3 5
2 3 6
2 3 7
2 4 5
2 4 6
2 4 7from itertools import product
for a, b, c in product(list1, list2, list3):
print(a, b, c)1 3 5
1 3 6
1 3 7
1 4 5
1 4 6
1 4 7
2 3 5
2 3 6
2 3 7
2 4 5
2 4 6
2 4 7